


はじめに
PostgreSQLの環境設定が終わっていない場合は下記を参照して下さい

前回でPostgreSQLの実行環境が整ったので、今回は下記を「簡単に」実践していきたいと思います。
※PostgreSQLガッツリリ使うようになったら、各項目毎にもっと深掘りしたいと思います。
今回の目標
メインで使用しているデータベースがInterSystems社のIRISになり、もっぱらIRIS系の記事を投稿しています。
そこで、いつも使用しているSampleネームスペースのクラス「developer.data.Sample.cls」を元に、PostgreSQLで同等のテーブルとサンプルデータを作成してみたいと思います。
下記は、IRISとPostgreSQLでの比較になります。
| IRIS | 名称 | PostgreSQLで作成する名称 |
|---|---|---|
| ネームスペース | Sample | 該当無し |
| データベース | SAMPLE SAMPLE-DATA | sample |
| スキーマ | developer_data | developer_data |
| クラス(テーブル)名 | Sample | sample |
| インデックス | idx nameIdx | idx nameidx |
IRISでは、スキーマとクラスが一体となっていますが、PostgreSQLでは別管理となっています。
意味合いは同じなので、後は慣れるだけです。
IRISの使用しているデータクラスが下記になります。
これをクラス情報を元に、PostgreSQLのテーブルを作成していきます。
Class developer.data.Sample Extends (%Persistent, %Populate)
{
Index idx On code [ PrimaryKey ];
Index nameIdx On (flg, code, name);
Property code As %String;
Property name As %String(POPSPEC = "##class(%Library.PopulateUtils).Name()");
Property document As %String(POPSPEC = "##class(%Library.PopulateUtils).Title()");
Property flg As %Boolean;
Property number As %Integer(POPSPEC = "##class(%Library.PopulateUtils).Integer()");
Storage Default
{
<Data name="SampleDefaultData">
<Value name="1">
<Value>%%CLASSNAME</Value>
</Value>
<Value name="2">
<Value>code</Value>
</Value>
<Value name="3">
<Value>name</Value>
</Value>
<Value name="4">
<Value>document</Value>
</Value>
<Value name="5">
<Value>flg</Value>
</Value>
<Value name="6">
<Value>number</Value>
</Value>
</Data>
<DataLocation>^developer.data.SampleD</DataLocation>
<DefaultData>SampleDefaultData</DefaultData>
<IdLocation>^developer.data.SampleD</IdLocation>
<IndexLocation>^developer.data.SampleI</IndexLocation>
<StreamLocation>^developer.data.SampleS</StreamLocation>
<Type>%Storage.Persistent</Type>
}
}IRIS上でのクラス「developer.data.Sample.cls」のデータは下記になります。
左辺の(1)~(10)がレコードIDとなり、右辺に表示しているのがデータ部になります。
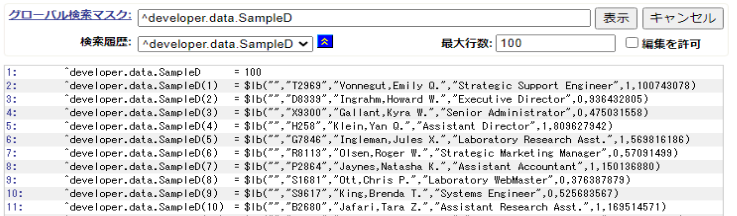
下記がインデックスのデータになります。
| インデックス名 | 属性 | プロパティの組み合わせ |
|---|---|---|
| idx | PrimaryKey | code |
| name | flg, code, name |
これらを元に、PostgreSQLで作成していきましょう。
データベースの操作
CREATE DATABASE データベースの作成
CREATE DATABASE name
[ [ WITH ] [ OWNER [=] user_name ]
[ TEMPLATE [=] template ]
[ ENCODING [=] encoding ]
[ LC_COLLATE [=] lc_collate ]
[ LC_CTYPE [=] lc_ctype ]
[ TABLESPACE [=] tablespace_name ]
[ CONNECTION LIMIT [=] connlimit ] ]設定可能なオプションがいくつかありますが、今回はシンプルに下記で作成しようと思います。
CREATE DATABASE sample;では、psqlで実行してみましょう。
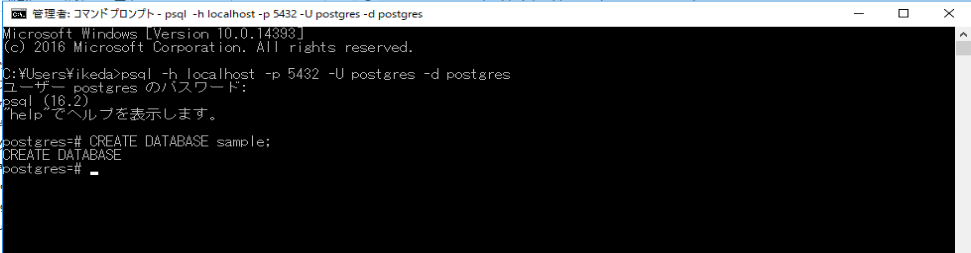
「CREATE DATABASE」の文字が表示されたので、作成成功です。
「\l」で確認してみましょう。
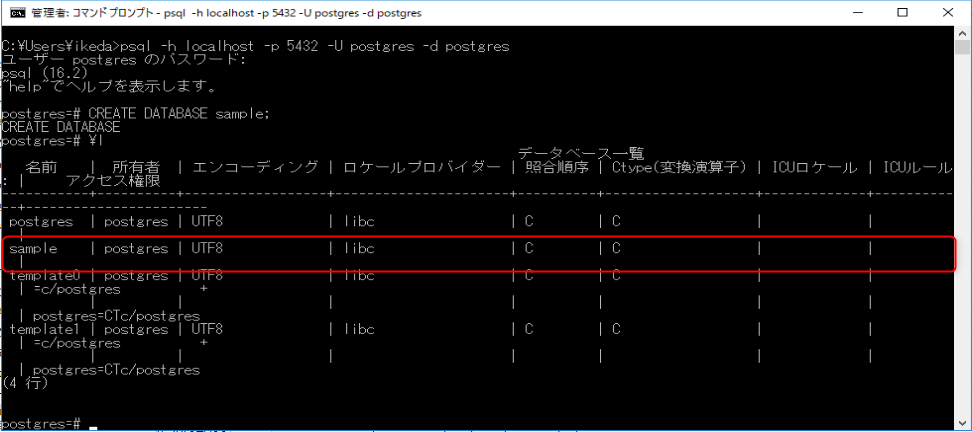
データベース「sample」が作成されているのが確認できます。
DROP DATABASE データベースの削除
DROP DATABASE [ IF EXISTS ] nameデータベース名を指定して削除を行います。
今回のコマンドは下記になります。
DROP DATABASE sample;では、psqlで実行してみましょう。

「DROP DATABASE」の文字が表示されたので、削除成功です。
今回はクエリを使用して、現データベースを確認してみます。
select datname,datdba,encoding,datcollate,datconnlimit from pg_database;では、psqlで実行してみましょう。

初期の3つが表示され、「sample」が削除された事を確認しました。
※このままだと先に進めないので、再度CREATE DATABASE sample;を実行します。
スキーマの操作
CREATE SCHEMA スキーマの作成
CREATE SCHEMA schema_name [ AUTHORIZATION user_name ] [ schema_element [ ... ] ]
CREATE SCHEMA AUTHORIZATION user_name [ schema_element [ ... ] ]設定可能なオプションが2つ程ありますが、今回はシンプルに下記で作成しようと思います。
CREATE SCHEMA developer_data;スキーマを作成するため、「sample」データベースに接続する必要があります。
下記コマンドをpsalで実行しましょう。
\c sample
データベースへの接続が完了しました。
「sample=#」と表示されているのも確認できます。
では、スキーマ作成コマンドを実行してみましょう。

「CREATE SCHEMA」の文字が表示されたので、作成成功です。
「\dn」で確認してみましょう。

スキーマ「developer_data」が作成されているのが確認できました。
DROP SCHEMA スキーマの削除
DROP SCHEMA [ IF EXISTS ] name [, ...] [ CASCADE | RESTRICT ]スキーマ名を指定して削除を行います。
今回のコマンドは下記になります。
DROP SCHEMA developer_data;では、psqlで実行してみましょう。

「DROP SCHEMA」の文字が表示されたので、削除成功です。
今回は下記クエリを使用して、スキーマの一覧を確認してみます。
select nspname, nspowner, nspacl from pg_namespace;
スキーマ「developer_data」が表示されていないので、削除が行われたのが確認できます。
※このままだと先に進めないので、再度CREATE SCHEMA developer_data;を実行します。

念のため先ほどのクエリを使って確認すると、末尾に追加されていました。
テーブルの操作
CREATE TABLE テーブルの作成
CREATE [ [ GLOBAL | LOCAL ] { TEMPORARY | TEMP } | UNLOGGED ] TABLE [ IF NOT EXISTS ] table_name ( [
{ column_name data_type [ COLLATE collation ] [ column_constraint [ ... ] ]
| table_constraint
| LIKE source_table [ like_option ... ] }
[, ... ]
] )
[ INHERITS ( parent_table [, ... ] ) ]
[ WITH ( storage_parameter [= value] [, ... ] ) | WITH OIDS | WITHOUT OIDS ]
[ ON COMMIT { PRESERVE ROWS | DELETE ROWS | DROP } ]
[ TABLESPACE tablespace_name ]
CREATE [ [ GLOBAL | LOCAL ] { TEMPORARY | TEMP } | UNLOGGED ] TABLE [ IF NOT EXISTS ] table_name
OF type_name [ (
{ column_name WITH OPTIONS [ column_constraint [ ... ] ]
| table_constraint }
[, ... ]
) ]
[ WITH ( storage_parameter [= value] [, ... ] ) | WITH OIDS | WITHOUT OIDS ]
[ ON COMMIT { PRESERVE ROWS | DELETE ROWS | DROP } ]
[ TABLESPACE tablespace_name ]
column_constraintには、次の構文が入ります。
[ CONSTRAINT constraint_name ]
{ NOT NULL |
NULL |
CHECK ( expression ) [ NO INHERIT ] |
DEFAULT default_expr |
UNIQUE index_parameters |
PRIMARY KEY index_parameters |
REFERENCES reftable [ ( refcolumn ) ] [ MATCH FULL | MATCH PARTIAL | MATCH SIMPLE ]
[ ON DELETE action ] [ ON UPDATE action ] }
[ DEFERRABLE | NOT DEFERRABLE ] [ INITIALLY DEFERRED | INITIALLY IMMEDIATE ]
また、table_constraintには、次の構文が入ります。
[ CONSTRAINT constraint_name ]
{ CHECK ( expression ) [ NO INHERIT ] |
UNIQUE ( column_name [, ... ] ) index_parameters |
PRIMARY KEY ( column_name [, ... ] ) index_parameters |
EXCLUDE [ USING index_method ] ( exclude_element WITH operator [, ... ] ) index_parameters [ WHERE ( predicate ) ] |
FOREIGN KEY ( column_name [, ... ] ) REFERENCES reftable [ ( refcolumn [, ... ] ) ]
[ MATCH FULL | MATCH PARTIAL | MATCH SIMPLE ] [ ON DELETE action ] [ ON UPDATE action ] }
[ DEFERRABLE | NOT DEFERRABLE ] [ INITIALLY DEFERRED | INITIALLY IMMEDIATE ]
and like_option is:
{ INCLUDING | EXCLUDING } { DEFAULTS | CONSTRAINTS | INDEXES | STORAGE | COMMENTS | ALL }
UNIQUE、PRIMARY KEYおよびEXCLUDE制約内のindex_parametersは以下の通りです。
[ WITH ( storage_parameter [= value] [, ... ] ) ]
[ USING INDEX TABLESPACE tablespace_name ]
EXCLUDE制約内のexclude_elementは以下の通りです。
{ column_name | ( expression ) } [ opclass ] [ ASC | DESC ] [ NULLS { FIRST | LAST } ]複雑でわかり難いです。
一先ず今回の目的である「Sample」テーブルを作成するコマンドになります。
CREATE TABLE developer_data.sample (
code varchar(5) PRIMARY KEY,
name varchar(30),
document varchar(50),
flg boolean,
number integer
);では、psqlで実行してみましょう。
改行が入っていても問題ありません。このままペーストOKです。
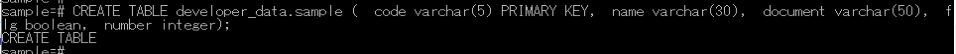
「CREATE TABLE」の文字が表示されたので、作成成功です。
では下記コマンドで、作成したテーブルを確認します。
\dt developer_data.*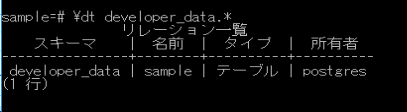
テーブル「sample」の作成を確認しました。
ついでに下記コマンドをpsqlで実行し、テーブルの構造も確認してみましょう。
\d developer_data.*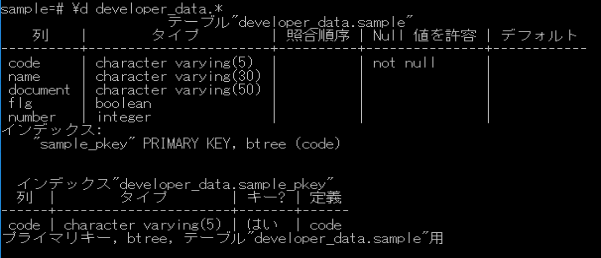
後は、「name」のインデックスを作成すれば、IRISで使用しているデータクラスがPostgreSQLで構築できます。
DROP TABLE テーブルの削除
DROP TABLE [ IF EXISTS ] name [, ...] [ CASCADE | RESTRICT ]スキーマ名を指定して削除を行います。
今回のコマンドは下記になります。
DROP TABLE developer_data.sample;
「DROP TABLE」の文字が表示されたので、削除成功です。
クエリを使用して、再度状況を確認してみます。
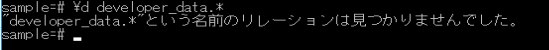
正常に削除された事を確認しました。
※インデックス作成のため、もう一度CREATE TABLEを実行します。
インデックス操作
CREATE INDEX インデックスの作成
CREATE [ UNIQUE ] INDEX [ CONCURRENTLY ] [ name ] ON table_name [ USING method ]
( { column_name | ( expression ) } [ COLLATE collation ] [ opclass ] [ ASC | DESC ] [ NULLS { FIRST | LAST } ] [, ...] )
[ WITH ( storage_parameter = value [, ... ] ) ]
[ TABLESPACE tablespace_name ]
[ WHERE predicate ]若干複雑でわかり難いです。
今回作成したいインデックスは「name」検索用なので、下記コマンドになります。
CREATE INDEX nameidx on developer_data.sample (flg, code, name);では、psqlで実行してみましょう。
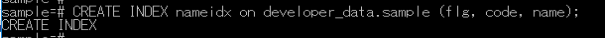
「CREATE INDEX」の文字が表示されたので、作成成功です。
では下記コマンドで、作成したテーブルを確認します。
\d developer_data.sample
これでようやく、IRISのデータクラスと同じテーブルが作成できました。
DROP INDEX インデックスの削除
DROP INDEX [ CONCURRENTLY ] [ IF EXISTS ] name [, ...] [ CASCADE | RESTRICT ]インデックス名を指定して削除を行います。
今回のコマンドは下記になります。
DROP INDEX developer_data.nameidx;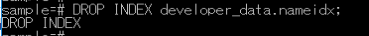
「DROP INDEX」の文字が表示されたので、削除成功です。
下記コマンドを使って、developer_data.sampleのインデックス情報を確認します。
\di developer_data.*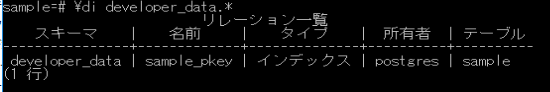
正常に削除された事を確認しました。
※レコード操作のため、もう一度CREATE INDEXを実行します。

レコード操作
レコード操作に関してはSQLのお作法になるので、IRISと共通したコマンドになります。
INSERT レコードの作成
[ WITH [ RECURSIVE ] with_query [, ...] ]
INSERT INTO table_name [ ( column_name [, ...] ) ]
{ DEFAULT VALUES | VALUES ( { expression | DEFAULT } [, ...] ) [, ...] | query }
[ RETURNING * | output_expression [ [ AS ] output_name ] [, ...] ]IRISの下記レコードを参考に、1レコード作成します。
^developer.data.SampleD(1)=$lb("","T2969","Vonnegut,Emily Q.","Strategic Support Engineer",1,100743078)全てのカラムにデータを格納するのであれば、下記コマンドで十分です。
IRISの%Booleanは1 or 0なので、PostgreSQL用にTRUE or FALSEに変更が必要です。
INSERT INTO developer_data.sample VALUES('T2969', 'Vonnegut,Emily Q.', 'Strategic Support Engineer', TRUE, 100743078);カラム指定でデータを格納する場合は、下記コマンドになります。
INSERT INTO developer_data.sample (code,name,document,flg,number) values ('T2969', 'Vonnegut,Emily Q.', 'Strategic Support Engineer', TRUE, 100743078);では、レコード作成と確認を行います。

1レコードの作成を確認しました。
UPDATE レコードの更新
[ WITH [ RECURSIVE ] with_query [, ...] ]
UPDATE [ ONLY ] table_name [ * ] [ [ AS ] alias ]
SET { column_name = { expression | DEFAULT } |
( column_name [, ...] ) = ( { expression | DEFAULT } [, ...] ) } [, ...]
[ FROM from_list ]
[ WHERE condition | WHERE CURRENT OF cursor_name ]
[ RETURNING * | output_expression [ [ AS ] output_name ] [, ...] ]サンプルデータの「flg: TRUE > FALSE」「number: 100743078 > 12345」に変更します。
UPDATE developer_data.sample SET flg = FALSE, number = 12345 where code = 'T2969';
「flg」「number」の値が変更されているのが確認できました。
DELETE レコードの削除
[ WITH [ RECURSIVE ] with_query [, ...] ]
DELETE FROM [ ONLY ] table_name [ * ] [ [ AS ] alias ]
[ USING using_list ]
[ WHERE condition | WHERE CURRENT OF cursor_name ]
[ RETURNING * | output_expression [ [ AS ] output_name ] [, ...] ]作成したレコードを削除するクエリは下記になります。
delete from developer_data.sample where code='T2969';
レコードが削除された事を確認しました。
使用したメタコマンドのまとめ
ここまでで使用したメタコマンドをまとめました。
| psqlコマンド | 説明 | 使用例 |
|---|---|---|
| \q | psql終了 | |
| \l | データベース一覧表示 | |
| \c [データベース名] | データベースに接続 | \c sample |
| \dn | スキーマ一覧表示 | |
| \dt [パターン] | リレーション一覧表示 | \dt developer_data.* |
| \d [名前] | テーブル・他表示 | \d developer_data.* |
| \di [パターン] | インデックス一覧表示 | \di developer_data.* |
おわりに
PostgreSQLの表面をさらっと触った形ですが、一先ずレコード作成までは行き着けました。
今回の計画では、直接PostgreSQLへのアクセスを行う事は無いので、一旦この状態で手を置きたいと思います。
PostgreSQLをもっと深掘りしたくなったら、再度記事を書きたいと思います。

