


初心者講座としてグローバルについて、ざっくり解説をしたいと思います。
本記事は、グローバルざっくり解説初回として、グローバルの基本操作について解説します。
グローバルの基本情報
グローバルのルール
グローバルのルールをまとめると、ざっとこんな感じです。
以降の説明はターミナルを使用するので、どこのネームスペースでも構わないので、ターミナルを立ち上げてください。
多次元グローバル
グローバルの添え字(ノード)は、他言語と異なり事前に配列数等を宣言する必要はありません。
上記ルールとストレージの容量内であれば、自由に配列を作成し追加する事が可能です。
グローバルの多次元構造は、他の言語に慣れ親しんだ方にとっては、なかなか直感的に捉えにくいかもしれません。
ですが「添え字(ノード)」の関係を、樹木の枝分かれ(ツリー構造)に例えると、ぐっとイメージしやすくなります。
下記の図は、^Sampleグローバルと第1、第2ノードをイメージしてみました。
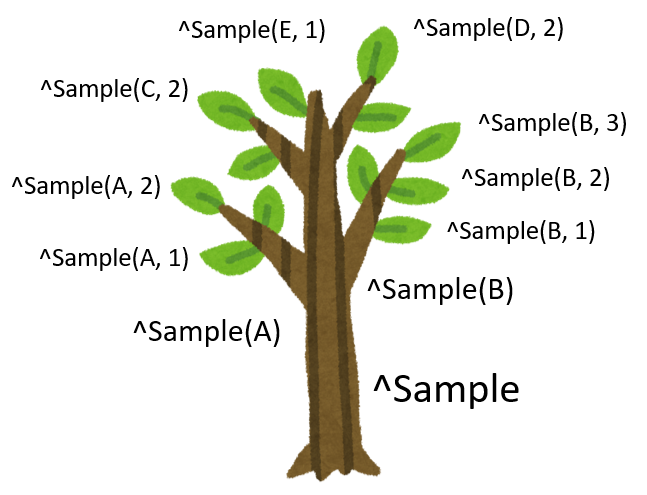
このイメージで、インターシステムズ・ジャパンの住所をデータ化してみると、こんなイメージになるでしょうか。
^Sample(“東京都”)=”首都”
^Sample(“東京都”,”新宿区”)=”県庁所在地”
^Sample(“東京都”,”新宿区”,”西新宿”,2,8,1)=”東京都庁”
^Sample(“東京都”,”新宿区”,”西新宿”,6,10,1)=”日土地西新宿ビル”
^Sample(“東京都”,”新宿区”,”西新宿”,6,10,1,”15階”)=”インターシステムズジャパン”
ノードの組み合わせと、グローバルのデータ値は自由な発想で構築して下さい。
kill文を実行すると、下位ノードまでバッサリ削除します。
上記例では、「k ^Sample(“東京都”,”新宿区”)」で実行すると、「^Sample(“東京都”)=”首都”」しか残りません。
枝をバッサリ切断して、剪定するイメージですね。
データの保存
グローバルにデータを保存するには、SETコマンドを使用します。
「set, SET, s, S, Set」と、大文字/小文字、省略と自由に記載可能です。
また、「:条件」で、条件がtrueの時にSET文を実行するような記述も可能です。
k ^Sample
s nm = "ビル"
set ^Sample("東京都")="首都"
SET ^Sample("東京都","新宿区")="県庁所在地"
s ^Sample("東京都","新宿区","西新宿",2,8,1)="東京都庁"
// 条件付きset文 ビル=true, 都庁=false
s:(nm="ビル") ^Sample("東京都","新宿区","西新宿",6,10,1)="日土地西新宿ビル"
s:(nm="都庁") ^Sample("東京都","新宿区","西新宿",6,10,1,"15階")="インターシステムズジャパン"
zw ^Sample
// ^Sample("東京都")="首都"
// ^Sample("東京都","新宿区")="県庁所在地"
// ^Sample("東京都","新宿区","西新宿",2,8,1)="東京都庁"
// ^Sample("東京都","新宿区","西新宿",6,10,1)="日土地西新宿ビル"同じ値を複数の変数に代入する事も可能です。
複数ループ前に初期化する際によく使用します。
k ^Sample
// 複数の変数/グローバルに対し、同時に値を代入する
s (code, name, key, mode) = ""
s ( ^Sample(1), ^Sample(2), ^Sample(3) ) = "テストデータ"
zw ^Sample
// ^Sample(1)="テストデータ"
// ^Sample(2)="テストデータ"
// ^Sample(3)="テストデータ"ノードのソート
ノードのソート機能は、グローバルの特徴的な機能の1つです。
ランダムにデータを作成しても、取り出すときは一定のルールで取り出す事が可能です。
【ソート例サンプル】
k ^Sample
s ^Sample("てすと")="てすと"
s ^Sample("test")="テスト"
s ^Sample(001)="1として認識する"
s ^Sample("001")="001として認識する"
s ^Sample(10)=10
zw ^Sample
// ^Sample(1)="1として認識する"
// ^Sample(10)=10
// ^Sample("001")="001として認識する"
// ^Sample("test")="テスト"
// ^Sample("てすと")="てすと"このグローバルのノードがソートされる特性を利用して、「自動ソートを前提としてデータ取得を行う」のは、頻繁に使われる機能になります。
データの取得($get)
データの取得を行うには、$GET($g)・$DATA($d)・$ORDER($o) 辺りをよく使います。
※カッコ内は、関数の省略です。大文字/小文字の区別なし。以降小文字で記載。
グローバルからデータを直接取得する事も可能ですが、もし取得する予定のグローバルが無かった場合、<UNDEFINED>エラーになります。
確実にそのグローバルがあると確信できない場合は、$getを使用する方が良いでしょう。
→逆に、存在が確信できる場合は、$getは不要です。
k ^Sample
s ^Sample("東京都")="首都"
s ^Sample("東京都","新宿区")="県庁所在地"
//-------------------------------------------------
// 直接取得
w ^Sample("東京都")
// 首都
//-------------------------------------------------
// $get
w $g(^Sample("東京都"))
// 首都
w $g(^Sample("埼玉"), "初期値") // グローバルが無いときは初期値が返る
// 初期値
w $g(^Sample("千葉")) // 省略するとnullが返る
// [null]
//-------------------------------------------------
// $data
s val = $d(^Sample("東京都","新宿区"), dt) // 変数「dt」にデータが格納される
w dt
// 県庁所在地
//-------------------------------------------------
// $order
s key = $o(^Sample("東京都", ""), 1, dt) // 変数「dt」にデータが格納される
w dt
// 県庁所在地※$data, $orderに関しては、機能も含め後述します
グローバルの存在有無を確認する($data)
グローバルの存在有無、下位ノードの存在有無を確認する関数として、$DATA($d)があります。
$dの戻り値をまとめると下記になります。
| 戻り値 | グローバルの有無 | 下位ノードの有無 |
|---|---|---|
| 0 | なし | なし |
| 1 | あり | なし |
| 10 | なし | あり |
| 11 | あり | あり |
また、第2引数に変数を配置すると、グローバルがある場合データを取得する事が可能です。
k ^Sample
s ^Sample("東京都")="首都"
s ^Sample("東京都","新宿区")="県庁所在地"
s ^Sample("埼玉県")="さいたま市"
s ^Sample("千葉県", "千葉市")="県庁所在地"
w $d(^Sample("神奈川県")) // データなし
// 0
w $d(^Sample("埼玉県")) // データあり
// 1
w $d(^Sample("千葉県")) // 下位ノードあり
// 10
w $d(^Sample("東京都")) // データ・下位ノードあり
// 11
//-------------------------------------------------
// データ取得
k dt
s flg = $d(^Sample("神奈川県"), dt) // グローバルが無いと、dtは何も変化がない
w dt
// <UNDEFINED> *dt
k dt
s flg = $d(^Sample("埼玉県"), dt) // グローバルが有ると、dtにデータが格納される
w dt
// さいたま市
//-------------------------------------------------
// bool値で返す方法2つ
// 1. グローバルの存在有無をbool値で返す
w $d(^Sample("神奈川県"))#10
// 0
w $d(^Sample("埼玉県"))#10
// 1
w $d(^Sample("千葉県"))#10
// 0
w $d(^Sample("東京都"))#10
// 1
// 2. 下位ノードの存在をbool値で返す
w $d(^Sample("神奈川県"))\10
// 0
w $d(^Sample("埼玉県"))\10
// 0
w $d(^Sample("千葉県"))\10
// 1
w $d(^Sample("東京都"))\10
// 1次や前のノードを取得する
ループ処理と、$OREDER($o)、$QUERY($q)、$NEXT($n)、$ZPREVIOUS($zp)等の関数を組み合わせる事で、グローバルを連続で取得する事が可能です。
【準備用関数】
各関数の動作を確認するため、下記コマンドをターミナルで実行し、プロセス・プライベートグローバルを作成してください。
makeData ;
k ^||sample
f pos1=1:1:5 {
s ^||sample(pos1) = "第一ノード("_pos1_")"
f pos2=1:1:($r(10)+1) {
s ^||sample(pos1, pos2) = "第二ノード("_pos2_")"
f pos3=1:1:($r(5)+1) {
s ^||sample(pos1, pos2, pos3) = "第三ノード("_pos3_")"
}
}
}
d makeData
zw ^||sampleでは、各関数の動作を確認していきましょう。
$order($o)
次のローカル変数、またはローカル変数やグローバル変数の添え字を返します。
動作が優秀すぎて、他の関数の出番はほぼ無いです。
$orderの引数は3つあり、「$o(グローバル/変数, 方向(略可), データ取得(略可))」となっています。
第2引数の「方向」は、1=昇順、2:降順になります。
※ 降順は、昇順より処理速度が遅いです。
では、基本的な動作の確認からいきます。
// 先ずは動作確認
w $o(^||sample("")) // 第2, 3引数は省略可
// 1
w $o(^||sample(""),-1)
// 5
w $o(^||sample(5))
// [null]
w $o(^||sample(1),-1)
// [null]
// データ取得
s key = $o(^||sample(1),1,data)
w data
// 第一ノード(2)
s key = $o(^||sample(5),-1,data)
w data
// 第一ノード(4)
// グローバルが無いと、変数「data」は何も操作されない
k data
s key = $o(^||sample(5),1,data)
w data
// <UNDEFINED> *dataではループ処理を確認しましょう。
ループの終了は、「QUIT(q)」コマンド等を使用して確実に終了させて下さい。
無限ループに入ります。
※もし無限ループが発生したら、「Ctrl + C」で強制終了です。
// $orderの第2, 3引数は、必要に応じて省略可能です
loopData ;
s (key1, key2, key3) = ""
f { s key1 = $o(^||sample(key1),1,data1) q:key1=""
f { s key2 = $o(^||sample(key1,key2),1,data2) q:key2=""
f { s key3 = $o(^||sample(key1,key2,key3),1,data3) q:key3=""
w !,data1,",",data2,",",data3
}
}
}
d loopData$orderの方向が昇順でも降順でも、最後はnullとなるので終了の条件はnullになります。
上位ノードも下位ノードも最後はnullとなるので、ループ前に一度初期化するだけで良いです。
※null以外でquitやcontinueする場合は、ループ前に都度初期化した方が良いかもしれません。
大事故に発生します。
$query($q)
ノードがいくつあるか分からない時、複数ノードを1つのループ処理で全て回したい時に利用します。
$queryは、グローバル参照全体を返すので、$orderとは動作が異なります。
$queryの引数も3つあり、「$o(グローバル/変数, 方向(略可), データ取得(略可))」となっています。
では、基本的な動作の確認です。
// 先ずは動作確認
w $q(^||sample("")) // 第2, 3引数は省略可
// ^||sample(1)
w $q(^||sample(""),-1)
// ^||sample(5,2,3) // ★ $orderと異なる点
w $q(^||sample(5,2,3)) // ★ $orderと異なる点
// [null]
w $q(^||sample(1),-1)
// [null]
// データ取得
s key = $q(^||sample(1),1,data)
w data
// 第二ノード(1) ★ $orderと異なる点
s key = $q(^||sample(5),-1,data)
w data
// 第三ノード(5) ★ $orderと異なる点ノードの数に影響を受けない為、$orderと異なるグローバルを参照する事が確認できます。
ではループ処理を確認しましょう。
ループの終了は、「QUIT(q)」コマンド等を使用して確実に終了させて下さい。
以下の関数も併せて覚えると、複雑な処理に対応できます。
| 関数名 | 省略 | 説明 |
|---|---|---|
| $QLENGTH | $ql | 変数内のノード数を返す |
| $QSUBSCRIPT | $qs | 変数名または添え字名を返す $qs(val, 0) // グローバル名/変数名 $qs(val, 1) // 第1ノード $qs(val, 2) // 第2ノード … |
では、$queryのループ処理を見てみます。
// $orderの第2, 3引数は、必要に応じて省略可能です
loopQuery9 ;
s gblNm = $na(^||sample("")) // 関節参照の用意「$name()」
f { s gblNm = $q(@gblNm,1,data) q:gblNm=""
w !,"ノード数:",$ql(gblNm)
,", グローバル名:",$qs(gblNm,0)
,", 第1:",$qs(gblNm,1)
,", 第2:",$qs(gblNm,2)
,", 第3:",$qs(gblNm,3)
,", データ:",data
}
d loopQuery9$queryでのループは、基本的に「関節参照(@)」となります。
そのため、処理時間は$orderより少し遅くなります。
また、適切にループを停止しないと、望まないノードまでループ対象としてしまうので、思わぬ事故が発生したりします。
$znext
非推奨
ドキュメントを探しても、もう見つからないですね・・・
$orderの昇順と同じ動作ですが、データの取得は行えません。
// 先ずは動作確認
w $n(^||sample(""))
// 1
w $n(^||sample(5))
// -1$nextは、最終ノードに到達すると「-1」を返します。
使いづらい・・・
$zprevious($zp)
非推奨
ドキュメントは見つかります。
$orderの降順と同じ動作になります。
これもデータの取得は行えません。
// 先ずは動作確認
w $zp(^||sample(""))
// 5
w $n(^||sample(5))
// [null]データのマージ
データのマージ(コピー)を行いたい時は、MERGE(m)コマンドを使用します。
// 全てのノードとデータを^||mgにマージする
m ^||mg = ^||sample
zw ^||mg
k ^||mg
m ^||mg(1,2) = ^||sample(1,2)
zw ^||mg
// ^||mg(1,2)="第二ノード(2)"
// ^||mg(1,2,1)="第三ノード(1)"
// ^||mg(1,2,2)="第三ノード(2)"
// ^||mg(1,2,3)="第三ノード(3)"
k ^||mg
m ^||mg = ^||sample(1,2)
zw ^||mg
// ^||mg="第二ノード(2)"
// ^||mg(1)="第三ノード(1)"
// ^||mg(2)="第三ノード(2)"
// ^||mg(3)="第三ノード(3)"コマンドなので、条件の付与も可能です
s flg = 1
m:(flg) ^||true = ^||sample(1,2)
m:('flg) ^||false = ^||sample(1,2)
zw ^||true
// ^||true="第二ノード(2)"
// ^||true(1)="第三ノード(1)"
// ^||true(2)="第三ノード(2)"
// ^||true(3)="第三ノード(3)"
zw ^||false
// なしネイキッド・グローバル
同じノード、又は下位のノードに対し、グローバル名や上位ノードを省略して記載する事が出来ます。
また、特殊変数「$ZREFERENCE($zr)」は、直前に参照したグローバルとノードを保持します。
ネイキッド・グローバルサンプル
s ^||Sample("東京都","千代田区")="https://www.city.chiyoda.lg.jp/"
s ^("中央区")="https://www.city.chuo.lg.jp/"
s ^("港区")="https://www.city.minato.tokyo.jp/"
s ^("新宿区")="https://www.city.shinjuku.lg.jp/"
s ^("新宿区","西新宿",6,10,1)="日土地西新宿ビル"
s ^(1,"15階")="インターシステムズジャパン"
zw ^||Sample
// ^||Sample("東京都","中央区")="https://www.city.chuo.lg.jp/"
// ^||Sample("東京都","千代田区")="https://www.city.chiyoda.lg.jp/"
// ^||Sample("東京都","新宿区")="https://www.city.shinjuku.lg.jp/"
// ^||Sample("東京都","新宿区","西新宿",6,10,1)="日土地西新宿ビル"
// ^||Sample("東京都","新宿区","西新宿",6,10,1,"15階")="インターシステムズジャパン"
// ^||Sample("東京都","港区")="https://www.city.minato.tokyo.jp/"
w ^||Sample("東京都","千代田区")
// https://www.city.chiyoda.lg.jp/
w ^("中央区")
// https://www.city.chuo.lg.jp/
w ^("新宿区")
// https://www.city.shinjuku.lg.jp/
w ^("新宿区","西新宿",6,10,1)
// 日土地西新宿ビル
// 一応こんなことも可能
w ^||Sample("東京都","中央区")
s key=""
f { s key=$o(^(key)) q:key="" w !,key }
// 中央区
// 千代田区
// 新宿区
// 港区
//-------------------------------------------------
// ネイキッド・インジケータ($zreference)
w ^||Sample("東京都","中央区")
// https://www.city.chuo.lg.jp/
w $zr
// ^||Sample("東京都","中央区")ネイキッドでのグローバル保存/取得は、通常の記述よりも高速に行われると聞いた事があります。
しかし、「直前」のグローバル参照を元に動作するので、その後のPG改修等で処理の流れが変わると(途中に別のグローバル参照を追加すると)、まったく予期しないデータが作成される事になります。
不具合を誘発する元になるので、ネイキッドを使用してのコーディングは、くれぐれも注意が必要です。
関節参照
関節参照とは、文字列に変換したグローバルに対し、「@」を付与してデータを取得する手法を指します。
下位ノードを求める場合は、「@」を連結して下位ノードを取得する事が可能です。
s gbl = "^||sample" // 文字列化
w @gbl@(1)
// 第一ノード(1)
// 文字列化は$name()を使用すると便利です
s gbl = $na(^||sample(1))
w gbl
// 下位ノードを求めるときは「@」を連結します。
// 例)@"^||sample(1)"@(1,2)
w @gbl@(1,2)
// 第三ノード(2)関節参照の使いどころとしては、同じグローバル構造を持つ異なるグローバル名を処理する際に使用すると、処理が1つにまとまります。
ただ、どのグローバルを参照しているか、その関数から判別するのが困難な為、改修漏れにつながる可能性もあります。
使用する際は、保守性も考慮に入れながらコーディングが必要になります。
まとめ
これまでをまとめると下記になります。
以上、グローバルの基本操作について解説しました。
本記事が、皆さまの実務や学びの中で、少しでもお役に立てれば幸いです。

