


本記事は、ブロックの断片化について解説します。
Q. ブロックの断片化って悪影響あるの?
A. 一部ループ処理で、処理速度が低下します。
ストレージの断片化しかり、ブロックの断片化しかり…「断片化」という字面のイメージから、「処理速度に影響がない」なんて、思う方は居ないでしょう。
先ずは、断片化の起こる原因を数点確認しつつ、実際に速度を検証してみたいと思います。
断片化について
そもそも、ブロックの断片化とはどのような状態を指すのでしょうか。
各ブロックには、番号が振られている事については、「グローバルざっくり解説#1」で解説しました。
同じグローバル名のデータ・ブロックが、連続して配置されていない事を「断片化」状態となります。
下記の例では、全61個のデータ・ブロックに対し、58個のデータ・ブロックが「連続」している事を示しています。

同じグローバル(インデックス)を再作成(%BuildIndices)したら、全てのデータブロックの「連続性が0=断片化」していました。

ただ、インデックスを再作成しただけなんですが・・・
断片化が起こる状況
システムを長期運用すると、自然にデータベースは断片化していきます。
断片化が発生する原因として、知りうる範囲では下記要因が挙げられます。
他にも断片化が発生する要因をご存じの方がいたら、ひっそり教えていただけると幸いです。
では、1つづつ確認していきましょう。
ブロックの充填率
充填率(Packing)は、データ・ブロックに格納されるデータ量の割合(%)になります。
1つ目のブロックにグローバルを格納する
下記グローバルを実行し、充填率の変化を確認してみます。
f pos=1:1:1015 s ^Packing(pos)=""この状態で、グローバルの容量を確認すると、充填率が脅威の「100%」と表示されます。

【データブロックの状態】
データブロックは1つで、容量が100%の状態
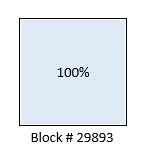
1つ目のブロックを溢れさせる
後は、徐々にグローバルを足していきましょう。
s ^Packing(1016)=""
s ^Packing(1017)=""
s ^Packing(1018)=""
s ^Packing(1019)=""
s ^Packing(1020)=""グローバルの容量を確認すると、ノードが1020の時に溢れました。

100%まで増加したのち、2つに分かれたので充填率「50%」に下がりました。
「① 初回のブロックが分割する時」は、ポインタ・ブロックも生成されるので、だいたい連続する事はないようです。
では、各ブロックの構成を確認してみます。
# 文字が灰色の行は、近隣の無関係なブロック情報です。
| ブロック番号 | ブロックタイプ | 開始グローバルノード | レコード数 | 割合 |
|---|---|---|---|---|
| 29892 | 下部ポインタ・ブロック | ^developer.data.PatientS(略) | ||
| 29893 | データ・ブロック | ^Packing | 917 | 90% |
| 29894 | データ・ブロック | ^BlockSearch | ||
| ====== | ========= | ============ | ==== | = |
| 34923 | データ・ブロック | ^ISCMethodWhitelist | ||
| 34924 | ポインタ・ブロック | – | ||
| 34925 | データ・ブロック | ^Packing(917) | 104 | 10% |
| 34926 | データ・ブロック | ^ROUTINE |
最初のデータ・ブロックだけ、大きく外れたブロック番号になっています。
また前後のブロックは、全くの無関係なデータ・ブロックなので、たまたま「# 29893」が空いていたのでしょう。
空いていた隙間に格納された事により、次のデータブロックが「# 34924」に格納されました。
また、「#34925」の隣も既に埋まっているため、次のデータブロックは断片化する事が確定しています。
「② 隣のブロックが埋まっていた時」を確認しました。
【データブロックの状態】
データブロックが2つになり、最初のデータブロックは充填率が90%に減少。
減った分は、2つ目のブロックに格納される。
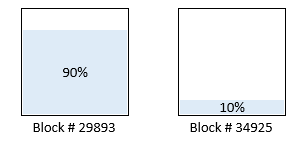
2つ目のブロックに追加のデータを詰める
さて、このままノードを1935まで増加させます。
f pos=1021:1:1935 s ^Packing(pos)=""グローバル全体の充填率は95%になりました。

ブロックの状況です。
最初のデータ・ブロックは変動がなく、2番目のブロックに新規グローバルが格納されています。
| ブロック番号 | ブロックタイプ | グローバルノード | レコード数 |
|---|---|---|---|
| 29893 | データ・ブロック | ^Packing ~ ^Packing(916) | 917 |
| 34925 | データ・ブロック | ^Packing(917) ~ ^Packing(1935) | 1,019 |
【データブロックの状態】
2つ目のデータブロックの充填率が100%になった。
1つ目のデータブロックは特に変化なし。
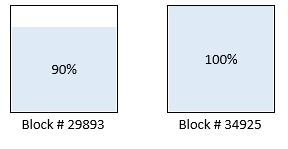
この先、さらにデータを追加していくと、2番目のデータ・ブロックの充填率は90%程度に下がり、3番目のデータ・ブロックが作成されると思われます。
そしてさらにデータを増加していくと、それが次から次へと繰り返されていく事になります。
1つ目のブロック(# 29893)に追加のデータを詰める
では、この状態で、1番目のデータ・ブロックにデータを追加したらどうなるでしょうか。
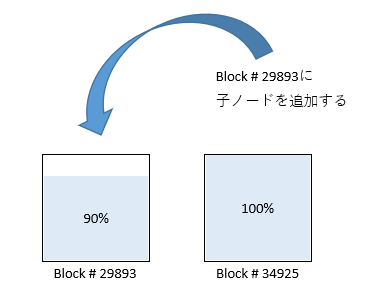
第2ノードを追加し、1番目のデータ・ブロックのデータ容量を増やします。
折角10%の空き容量があるのですが、実験なので仕方なしです(笑
f pos=1:1:110 s ^Packing(500, pos)=""1番目のデータ・ブロックが分割されました。

ブロックの状況を確認します。
| ブロック番号 | ブロックタイプ | グローバルノード | レコード数 |
|---|---|---|---|
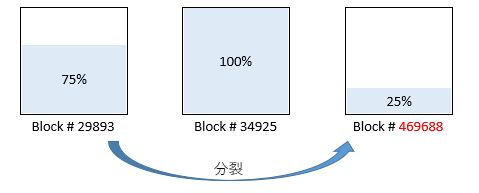
| 29893 | データ・ブロック | ^Packing ~ ^Packing(660) | 771 |
| 469688 | データ・ブロック | ^Packing(661) ~ ^Packing(916) | 256 |
| 34925 | データ・ブロック | ^Packing(917) ~ ^Packing(1935) | 1,019 |
新規に分裂したデータ・ブロックは、かなり離れた位置に作成されました。
これが「③ グローバル追加・値の増加によってデータ・ブロックが分割した時」になります。
断片化が激しいですね。
【データブロックの状態】
1つ目のデータブロックが、データ量の増加によって分割。
2つ目のデータブロックは変化なし。
以上、ブロックが断片化する要因を色々見てきました。
次は、断片化した状態と、連続した状態での処理速度を確認します。
処理速度を比較する
意図的に断片化を引き起こして、断片化したデータベースと、断片化していないデータベースで処理速度を比較してみたいと思います。
準備
データ・クラスを5個用意し、Populateで5個同時に100万件のデータを生成します。
同時にデータを作成する事で、意図的に断片化を発生させます。
※Populateの実行は、5個のターミナルを使用するか、jobコマンドで行って下さい。
データ作成後、データベース(DATファイル)をコピーして、片方にデフラグを実行します。
これで同じデータを持った「断片化したデータベース」と「非断片化したデータベース」が用意できました。
参考)作成したグローバルの状態
| グローバル名 | ブロック数 | 断片化状態 Packing | 断片化状態 Contig. | デフラグ後 Pcking | デフラグ後 Contig. |
|---|---|---|---|---|---|
| developer.data.Defrag1D | 23,807 | 89% | 51 | 89% | 23,806 |
| developer.data.Defrag1I | 16,792 | 76% | 10,837 | 76% | 16,791 |
グローバルを単純にループさせる
このグローバルのノード(レコードID)を全件ループして、処理速度の差を検証したいと思います。
ClassMethod defLoop()
{
s start = $zh
s rowId = ""
f { s rowId = $o(^developer.data.Defrag1D(rowId),1,data) q:rowId=""
}
w !,$zh - start
}【検証結果】
| 項目 | 1回 | 2回 | 3回 | 4回 | 5回 | 6回 | 7回 | 8回 | 9回 | 10回 | 平均 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 断片化 | 8.25 | 7.87 | 7.71 | 8.33 | 8.81 | 7.81 | 7.94 | 8.96 | 8.10 | 8.40 | 8.22 |
| デフラグ後 | 8.01 | 7.43 | 7.21 | 7.29 | 6.88 | 7.06 | 6.14 | 6.09 | 7.56 | 7.15 | 7.08 |
100万件をループするだけで、1秒の差が生まれました。
SQLを実行し、レコードの検索を行う
次はSQLで、全レコードの30%のデータを検索してみたいと思います。
ClassMethod sql(name As %String)
{
s start = $zh
&sql(
declare C200 cursor for
select 性別,生年月日,ABO血液型 into:性別,:生年月日,:ABO血液型
from developer_data.Defrag1
where 漢字氏名 like :name or カナ氏名 like :name
)
&sql(open C200)
f {
&sql(fetch C200)
if (SQLCODE=100) { quit }
}
&sql(close C200)
w !,$zh-start
}【検証結果】
| 項目 | 1回 | 2回 | 3回 | 4回 | 5回 | 6回 | 7回 | 8回 | 9回 | 10回 | 平均 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 断片化 | 21.9 | 21.3 | 19.8 | 20.7 | 20.0 | 19.8 | 22.4 | 21.4 | 22.6 | 20.5 | 21.0 |
| デフラグ後 | 16.7 | 17.7 | 19.4 | 18.1 | 14.9 | 16.7 | 17.3 | 17.1 | 17.7 | 15.0 | 17.1 |
レコード全体の30%程を検索するだけで、4秒の差が生まれています。
ディスクからデータを読み取るとき、どうしてもシークが発生します。
これは、構造上仕方のない動作ですが、データブロックが断片化していると、多少の影響が出ているようです。
※ 検証端末=ハード・ディスク
デフラグを解消する
デフラグの解消については、下記を参照してください。

管理ポータルで、お手軽にデフラグする方法を少し触れたいと思います。
[システムオペレーション] > [データベース] で「データベース]画面を起動します。
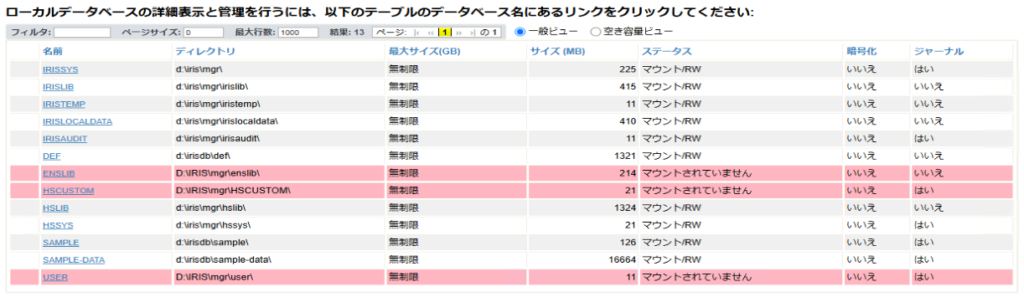
デフラグを行うデータベース名をクリックすると、「データベースの詳細」画面が起動します。
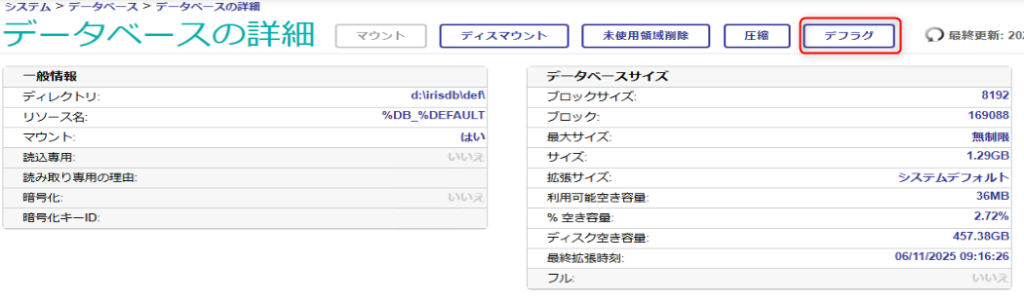
後は「デフラグ」ボタンをクリックするだけです。
楽ちんです。
デフラグ実行時に、データベース(DATファイル)が肥大化する事があります。
ストレージの容量確保をご確認下さい。
肥大化したデータベースは、「圧縮」で小さくする事が可能です。
まとめ
これまでの結果をまとめると下記になります。
定期的なメンテナンスを行うことで、初期の処理速度を維持する事が可能です。
以上、ブロックの断片化について解説しました。
本記事が、皆さまの実務や学びの中で、少しでもお役に立てれば幸いで

