


本記事は、グローバルのループ処理の高速化について解説します。
Q. ループを早くする方法はあるの?
A. 特定の条件であれば、早くする事は可能
すでに、下記記事にてループ処理を早くする方法は紹介しています。
とは言えこの2つの記事は、あくまで環境を整える事によって、処理を早くする方法であり、ロジック的に早くする方法ではありません。
この記事で紹介するのは、2つのルールに則る事でループ処理を早くする方法になります。
では、この2点について確認していきましょう。
ランダムアクセスを回避する
先ずは、ランダムアクセスとは何ぞや?から解説します。
下記に、2つのグローバル「インデックス」と「データ」があります。
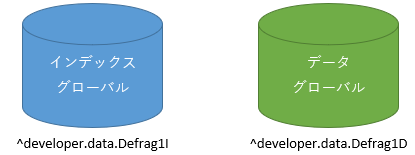
目的のデータ・グローバルを取得するには、先ずインデックス・グローバルを検索し、データ・グローバルの「レコードID」を取得する事が多いと思います。
下記例で言えば、「名前」と「カナ氏名」から患者ID(patientId)を取得するには、インデックス・グローバルをループして検索するロジックになると思います。
【サンプルPG】
ClassMethod RSearch(name As %String = "", kana As %String = "")
{
// 利用するインデックス
// Index idxName On (漢字氏名, カナ氏名);
s start = $zh
s (idxNm, idxKana, rowId) = ""
f { s idxNm = $o(^developer.data.Defrag1I("idxName", idxNm)) q:idxNm=""
continue:(name'="")&&(idxNm'[name)
f { s idxKana = $o(^developer.data.Defrag1I("idxName", idxNm, idxKana)) q:idxKana=""
continue:(kana'="")&&(idxKana'[kana)
f { s rowId = $o(^developer.data.Defrag1I("idxName", idxNm, idxKana, rowId)) q:rowId=""
// データ取得
s $lg(,,,,,,,,,,,patientId,漢字氏名,カナ氏名,,,,,,) = ^developer.data.Defrag1D(rowId)
w !,patientId,",",漢字氏名,",",カナ氏名
}
}
}
s time = $zh - start
s $li(^ZzTime, *+1)=time
}「名前」と「カナ氏名」の検索方法は色々ありますが(今回は含む検索)、インデックス・グローバルのノード末尾である「レコードID」を取得し、データグローバルにアクセスする方法は変わらないと思います。
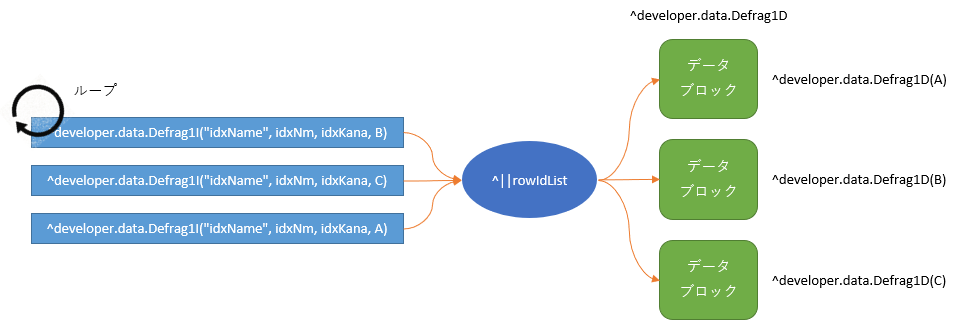
これを図解すると下記になります。
インデックス・グローバルをループした場合、ノード末尾の「レコードID」はランダムに存在しているため、「データ・グローバルへのアクセスもランダム」になります。

では、このロジックをループ速度が改善する方向で改修してみましょう!
今回の改修は、データ・ブロックへのアクセスがランダムとなっている箇所に着目します。
【改修案】
・インデックス・グローバルのループで「プロセス・グローバル」にレコードIDを格納する
・プロセス・グローバルをループし、データ・ブロックへアクセスする。
一見、「2回ループさせる事」が無駄に思えると思います。
しかし、一旦プロセス・グローバルを使用して「レコードIDをソート」させる事で、データ・ブロックへのランダムアクセスが回避できます。
ClassMethod CSearch(name As %String = "", kana As %String = "")
{
// 利用するインデックス
// Index idxName On (漢字氏名, カナ氏名);
s start = $zh
k ^||rowIdList
s (idxNm, idxKana, rowId) = ""
f { s idxNm = $o(^developer.data.Defrag1I("idxName", idxNm)) q:idxNm=""
continue:(name'="")&&(idxNm'[name)
f { s idxKana = $o(^developer.data.Defrag1I("idxName", idxNm, idxKana)) q:idxKana=""
continue:(kana'="")&&(idxKana'[kana)
f { s rowId = $o(^developer.data.Defrag1I("idxName", idxNm, idxKana, rowId)) q:rowId=""
s ^||rowIdList(rowId) = ""
}
}
}
// データ取得
f { s rowId = $o(^||rowIdList(rowId)) q:rowId=""
s $lg(,,,,,,,,,,,patientId,漢字氏名,カナ氏名,,,,,,) = ^developer.data.Defrag1D(rowId)
w !,patientId,",",漢字氏名,",",カナ氏名
}
s time = $zh - start
s $li(^ZzTime, *+1)=time
}図解するとこんなイメージです
では、この両ロジックの処理速度を計測します。
レコード100万件に対し、32%になる32万件を検索しています。
| 項目 | 平均 | 1回 | 2回 | 3回 | 4回 | 5回 | 6回 | 7回 | 8回 | 9回 | 10回 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| ランダム | 143.8 | 140.5 | 143.7 | 151.1 | 144.9 | 137.9 | 142.7 | 140.0 | 144.5 | 148.4 | 144.7 |
| 改善後 | 49.9 | 50.2 | 49.9 | 52.3 | 51.3 | 46.0 | 51.4 | 52.4 | 51.0 | 44.9 | 49.7 |
同じグローバルで検索を行っていますが、処理の工程の違いによって処理速度に差が生まれている事が確認できます。
目的のグローバルへアクセスする前に、一端ソートする処理をワンクッション入れるのを検討したいですね。
ループ回数を減らす
ループの回数を減らす・・・と言われても。
と思うかもしれませんが、一応状況に応じて何とかできなくもないです。
その1:レコードIDのような連続した数値の場合
レコードIDのような、連続した数値をグローバルのノードにする場合、ビットに変換する方法があります。
ビットを使用すると、複数のレコードIDを少ないデータ量で管理する事が可能です。
今回は、64,000件のレコードを1ノードで管理するように修正しました。
データ部をビットに変更する事により、全体のデータ量が削減されます。
そのため、プロセスグローバルを使用せず、通常の変数で運用します。
ClassMethod CSearch2(name As %String = "", kana As %String = "")
{
// 利用するインデックス
// Index idxName On (漢字氏名, カナ氏名);
s start = $zh
k bitDt
s (idxNm, idxKana, rowId) = ""
f {
s idxNm = $o(^developer.data.Defrag1I("idxName", idxNm)) q:idxNm=""
continue:(name'="")&&(idxNm'[name)
f {
s idxKana = $o(^developer.data.Defrag1I("idxName", idxNm, idxKana)) q:idxKana=""
continue:(kana'="")&&(idxKana'[kana)
f {
s rowId = $o(^developer.data.Defrag1I("idxName", idxNm, idxKana, rowId)) q:rowId=""
s $bit(bitDt(rowId\64000+1), rowId#64000+1)=1
}
}
}
// データ取得
s chkKey = ""
f { s chkKey = $o(bitDt(chkKey),1,chkBitDt) q:chkKey=""
s SearchKey = 0
f { s SearchKey = $bitfind(chkBitDt, 1, SearchKey + 1) q:SearchKey=0
s rowId = (chkKey - 1) * 64000 + SearchKey - 1
s $lg(,,,,,,,,,,,patientId,漢字氏名,カナ氏名,,,,,,) = ^developer.data.Defrag1D(rowId)
w !,patientId,",",漢字氏名,",",カナ氏名
}
}
s time = $zh - start
s $li(^ZzTime, *+1)=time
}| 項目 | 平均 | 1回 | 2回 | 3回 | 4回 | 5回 | 6回 | 7回 | 8回 | 9回 | 10回 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| ランダム | 143.8 | 140.5 | 143.7 | 151.1 | 144.9 | 137.9 | 142.7 | 140.0 | 144.5 | 148.4 | 144.7 |
| 改善後 | 49.9 | 50.2 | 49.9 | 52.3 | 51.3 | 46.0 | 51.4 | 52.4 | 51.0 | 44.9 | 49.7 |
| bit化 | 47.4 | 49.4 | 45.3 | 49.7 | 46.8 | 47.7 | 48.1 | 47.9 | 44.7 | 46.3 | 48.0 |
少しだけ処理速度が向上しました。
プロセス・グローバルを変数に変更した事も影響してそうですが(汗
その2:ノードが複数の場合、ノードをまとめる
先ほどのインデックスを元に、2つのグローバルを作成して、ループ速度を比較します。
念のため、デフラグをかけておきます。
グローバルの構造上、ノードが1つの方がデータ量(ブロック数)が多いですね。

では、検証用のプログラムを作成して、処理速度を検証しましょう。
ClassMethod survery()
{
s start = $zh
s cnt = 0
s (idx1,idx2,idx3)=""
f {
s idx1 = $o(^survey1(idx1))
q:idx1=""
f {
s idx2 = $o(^survey1(idx1, idx2))
q:idx2=""
f {
s idx3 = $o(^survey1(idx1, idx2, idx3))
q:idx3=""
s cnt = cnt + 1
}
}
}
s time = $zh - start
s $li(^ZzTime1, *+1)=time
w !,cnt
s start = $zh
s cnt = 0
s idx = ""
f {
s idx = $o(^survey2(idx))
q:idx=""
s cnt = cnt + 1
}
s time = $zh - start
s $li(^ZzTime2, *+1)=time
w !,cnt
}| 項目 | 平均 | 1回 | 2回 | 3回 | 4回 | 5回 | 6回 | 7回 | 8回 | 9回 | 10回 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 複ノード (^survery1) | 4.6 | 4.5 | 4.8 | 4.1 | 5.1 | 3.9 | 4.0 | 5.2 | 4.9 | 4.9 | 5.1 |
| 単ノード (^servery2) | 2.6 | 2.0 | 2.5 | 2.7 | 2.8 | 3.0 | 2.5 | 2.6 | 2.7 | 2.6 | 2.4 |
結果は、複数のノードよりも1つのノードの方が、ループ処理が早い事が分ります。
なせ差が生まれるのか、原因を確認するため、処理の動きを確認してみましょう。
| 処理 | 時間 | 処理数 | Disc Upn | Disc Bpn | Disc Data | Buf Dir | Buf Upn | Buf Bpn | Buf Data |
|---|---|---|---|---|---|---|---|---|---|
| $o(^survey1(A)) | 0.087291 | 20,481 | 1 | 1 | 78 | 1 | 0 | 0 | 1092 |
| $o(^survey1(A,B)) | 3.050884 | 1,019,178 | 0 | 0 | 2,653 | 0 | 0 | 0 | 1 |
| $o(^survey1(A,B,C)) | 3.419384 | 1,998,698 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| $o(^survey2(A)) | 3.206828 | 1,000,001 | 1 | 1 | 3,141 | 1 | 0 | 0 | 1 |
Dir=ディレクトリ・ブロック, Upn=上部ポインタ・ブロック, Bpn=下部ポインタ・ブロック, Data=データ・ブロック
今回の処理では、ループの終了条件を「null」としている為、該当ノード数+nullの回数分ループする事になります。
そのため、元のレコード数を超える回数分のループが発生する事になります。
※ 今回の検証では第3ノードのループが、レコード数の2倍程回っている事が分ります。
このように、ノード数を減らす事でループ処理の速度を向上させることが可能です。
とは言え、この方法の欠点は、連結する各文字列の文字数が一致していない場合、データをソートして取得できない点ですね・・・(汗。
データを単純に集めたい場合や、別途ソートする手段がある場合は、お勧めの方法です。
まとめ
これまでの結果をまとめると下記になります。
以上、ループ処理の処理速度向上について解説しました。
本記事が、皆さまの実務や学びの中で、少しでもお役に立てれば幸いです。

