


本記事は、大量データの書き込みについて解説します。
大量データを高速で書き込む方法はあるの?
A. 特定の条件であれば、早くする事は可能
例えば、部屋の整理をしている時を想像して下さい。
終わりの見えない荷物量で、大小様々な箱をランダムに手渡されて、小さいもの順に整理して片付けろと言われたらどうでしょう?
「全体の量を把握したい」「小さいものから手渡して欲しい」と思いませんか?
グローバルの保存も同様です。
ランダムにデータを書き込むと、ブロックの分割が頻繁に発生し、最終的な処理時間は伸びる事になるでしょう。
とは言え、整頓しながら書き込むのも、中々大変です。
本記事は小ネタになりますが、知っていると少し差がつく関数をご紹介致します。
$SORTBEGIN, $SORTEND
グローバルのノードがランダムかつ大量データを登録する場合は、この$sortBegin ~ $sortEnd(以下$sortBegin/End)を使用すると、処理速度が段違いに変わってきます。
この関数は、データ登録前にクラッチ・バッファに書き出し、ソートした状態で書き込む為、高速で処理する事が可能になります。
【サンプルPG】
インデックスグローバルをループしつつ、グローバル「^sortData」に名称とカナ名称を保存する処理になります。
レコード数は100万件で実施しています。
ClassMethod sortBeginTest(flg)
{
s start = $zh
s:(flg) ret = $sortBegin(^sortData)
s (idxNm, idxKana, rowId) = ""
f {
s idxNm = $o(^developer.data.Defrag1I("idxName", idxNm))
q:idxNm=""
f {
s idxKana = $o(^developer.data.Defrag1I("idxName", idxNm, idxKana))
q:idxKana=""
f {
s rowId = $o(^developer.data.Defrag1I("idxName", idxNm, idxKana, rowId))
q:rowId=""
// データの書き込み
s ^sortData(rowId) = $lb(idxNm, idxKana)
}
}
}
s:(flg) ret = $sortEnd(^sortData)
s time = $zh - start
s $li(^ZzTime, *+1)=time
k ^sortData
}$sortBegin/Endのある/なしで処理速度を比較しました。
| 項目 | 1回 | 2回 | 3回 | 4回 | 5回 | 6回 | 7回 | 8回 | 9回 | 10回 | 平均 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| あり | 8.74 | 8.85 | 9.57 | 8.68 | 8.74 | 8.49 | 8.83 | 8.98 | 9.77 | 8.31 | 8.90 |
| なし | 16.57 | 16.86 | 12.25 | 16.45 | 17.25 | 15.27 | 15.13 | 16.91 | 15.77 | 14.35 | 15.68 |
結果を比較すると、$sortBegin/Endの設定がない場合、2倍近く処理が遅くなっているのが分かります。
では、この両者のデータ・ブロックを確認してみましょう。
| 項目 | ブロック数 | データ量(バイト) | Packing | Contig. |
|---|---|---|---|---|
| あり | 6,044 | 44,262,024 | 90% | 6,035 |
| なし | 7,901 | 44,283,808 | 69% | 0 |
データ・ブロックの連続性「Contig.」の値や、充填率「Packing」に大きな開きがあるのが確認できます。
この状態では、今後のデータ運用にも差が出てくる事になるでしょう。
これらの結果を見ると、$sortBegin/Endの利用価値が分かります。
※参考程度
100万件のレコードだけでは、検証に心もとないので、各レコード数毎に10回ずつ試行し、平均値をグラフ化してみました。
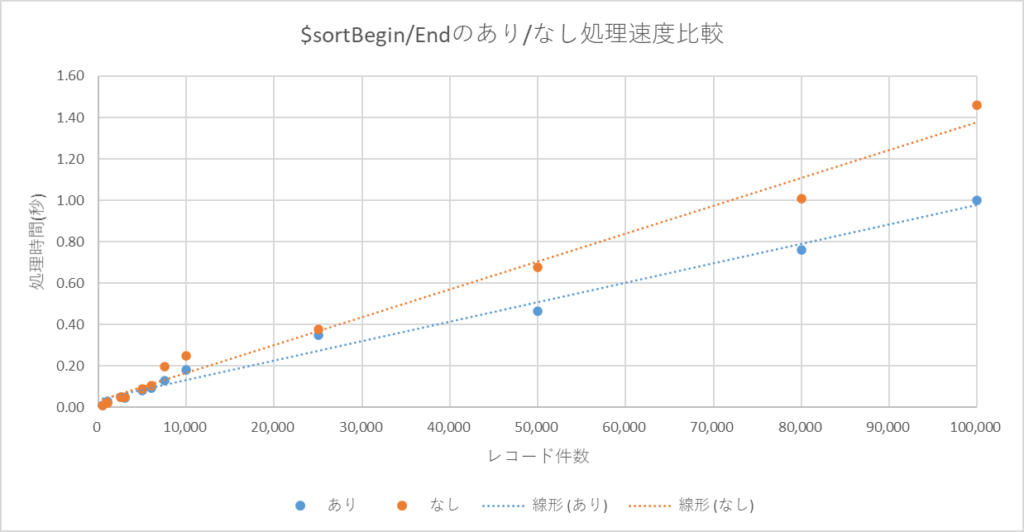
今回の検証に関しては、一先ず$sortBegin/Endは付けておいた方がよさそうな感じですね。
あまり効果が期待できないケース
タイトル通り、$sortBegin/Endを行っても、あまり効果が期待できないケースが存在します。
$sortBegin/Endの仕様は「クラッチ・バッファに書き出し、ソートした状態で書き込む」ので、そもそもソートされた状態での登録に関しては、効果があまり期待できない状態になります。
下記ケースで検証してみましょう。
【サンプルPG】
レコードIDを昇順でループしつつ、グローバル「^sortData」のキーもレコードIDで登録しています。
これにより、最初からソートされた状態で^sortDataに登録しています。
ClassMethod sortBeginTest2(flg)
{
s start = $zh
s:(flg) ret = $sortBegin(^sortData)
s rowId = ""
f {
s rowId = $o(^developer.data.Defrag1D(rowId),1,data)
q:rowId=""
// データの書き込み
s ^sortData(rowId) = data
}
s:(flg) ret = $sortEnd(^sortData)
s time = $zh - start
s $li(^ZzTime, *+1)=time
k ^sortData
}$sortBegin/Endのある/なしで処理速度を比較しました。
| 項目 | 1回 | 2回 | 3回 | 4回 | 5回 | 6回 | 7回 | 8回 | 9回 | 10回 | 平均 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| あり | 17.5 | 17.2 | 17.5 | 17.8 | 19.0 | 17.3 | 17.8 | 15.4 | 17.5 | 16.7 | 17.4 |
| なし | 20.9 | 20.6 | 20.1 | 18.9 | 18.9 | 21.4 | 18.7 | 19.3 | 20.4 | 18.6 | 19.8 |
ランダムでデータ登録した時と比較して、劇的な差はありません。
まぁ、無いよりはマシかな、程度です。
同じ処理で、各レコード数毎に試行回数10回の平均値をグラフ化してみました。
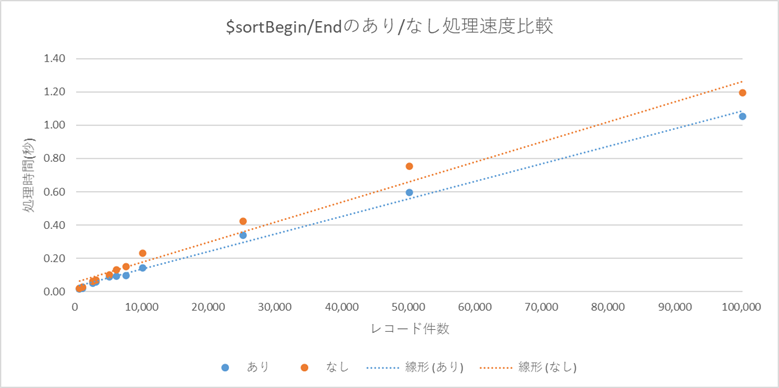
どのレコード数でも明確な効果を得られた感じではないです。
※あくまでも今回の検証の話に限ってです。
あってもなくても大して変わらない感じですね。
とは言え、どちらのケースでも、データ量が少なければ少ないほど、恩恵は小さくなります。
まとめ
これまでの結果をまとめると下記になります。
以上、大量データの書き込みについて解説致しました。
本記事が、皆さまの実務や学びの中で、少しでもお役に立てれば幸いです。

