


本記事は、グローバルのループ処理の高速化について引き続き解説します。
Q. ループを早くする方法はあるの?
A. 特殊な条件・環境であれば、早くする事は可能
同じ質問を「グローバルざっくり解説#6」で行いましたが、内容は異なります。
本記事は、データ・ブロックのサイズを変更する事で、ループ処理の速度が向上する事を検証したいと思います。
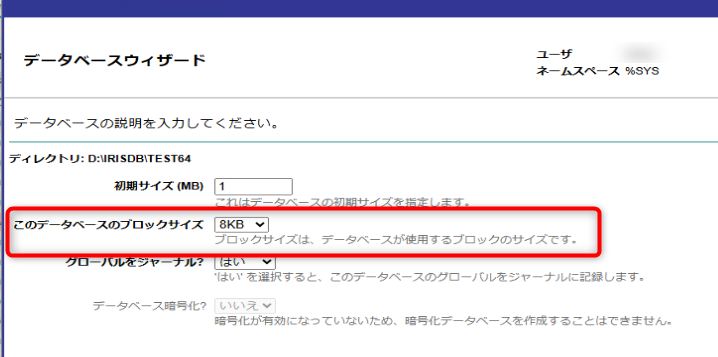
データベース作成時のウィザードで良く見る、この項目「ブロック・サイズ」を操作する形になります。
では、確認していきましょう。
ブロック・サイズとは?
データベース作成時に設定する項目で、一度データベースを作成してしまうと変更する事が出来ない項目になります。
ブロック・サイズを変更すると、1つのデータ・ブロックに格納されるグローバル数が増加します。
格納されるグローバル量が増加すれば、ディスクアクセスの回数がその分減ります。
アクセス回数が減れば、処理速度が向上する事になります。
風が吹けば桶屋が儲かる的な感じですね。
以上より、ブロック・サイズを増やす事のメリットになります。
とは言え、ブロック・サイズの基本が「8kb」である事には、理由があります。
以下は、ブロック・サイズを増加した時(ラージ・ブロック・サイズ)の注意点になります。
そもそもシステム系のデータベース「IRISSYS」等は、8KBデータベースで構成されていたりするので、完全に8KBデータベースを無くす事はできません。
また、インデックス系のグローバル等は、8KBのデータベースで運用する方が良いです。
そのため、上記デメリットの問題が解消できない限り、使用は控えた方が良いと思います。
各サイズの選択肢を開放する方法
ブロック・サイズの変更は、初期インストールでは選択できないため、選択肢を開放する設定が必要です。
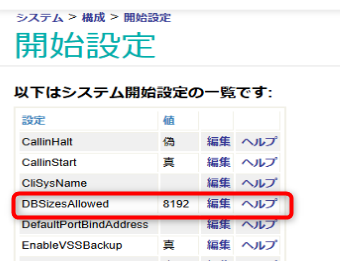
管理ポータルを起動し、[システム管理] > [構成] > [追加の設定] > [開始]と移動し、開始設定画面を起動します。
項目名「DBSizesAllowed」の「編集」をクリックし、開放したいラージ・ブロック・サイズにチェックを入れて、ボタン「保存」をクリックします。
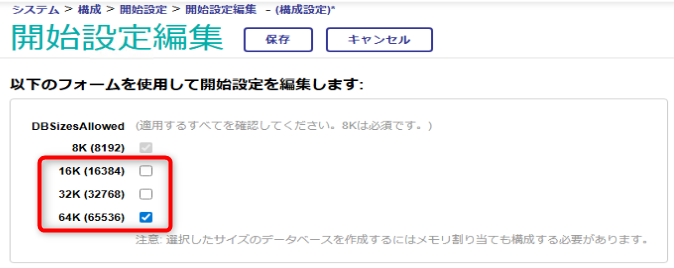
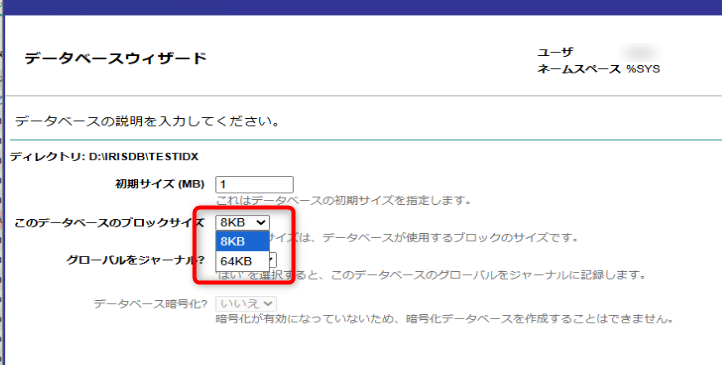
今回は、64kBサイズを開放しました。
ウィザードのブロックサイズ選択で、64KBの選択肢が表示すれば成功です。
データベース・キャッシュ(グローバル・バッファ)の設定
ラージ・ブロック・サイズのデータベースを運用する場合、グローバル・バッファの値を設定する必用があります。
管理ポータルより、[システム管理] > [構成] > [システム構成] > [メモリと開始設定]と移動し、メモリと開始設定画面を起動します。
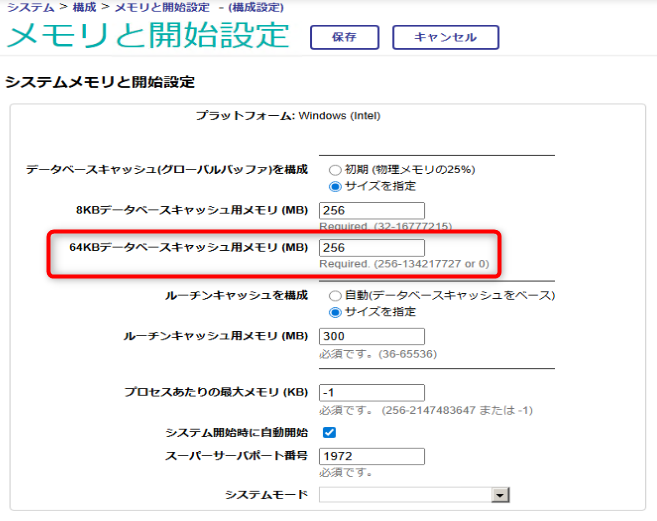
グローバルにアクセスすると、ブロックの全グローバルをメモリにキャッシュします。
ラージ・ブロック・サイズのデータベースを利用する場合、1回のグローバルアクセスでキャッシュするデータ量が増える為、少なくとも8KBの設定より多くのメモリを設定する必用があります。
速度検証
諸々の準備が整ったので、ループ速度の検証を行いたいと思います。
今回の検証では、データベースの構成を下記にしました。
下記イメージに沿って作成します。
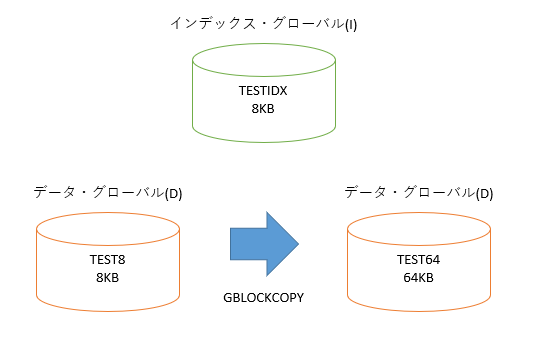
100万件のデータを作成しました。
データベースのブロック構成は下記になります。
| DB名 | 種類 | ブロック数 | データ量 | Packing | Contig. |
|---|---|---|---|---|---|
| TESTIDX | インデックス | 7,227 | 44,678,476 | 76% | 7,226 |
| TEST8 | データ(8KB) | 23,808 | 172,693,948 | 89% | 23,778 |
| TEST64 | データ(64KB) | 2,924 | 172,130,356 | 90% | 2.923 |
64KBのデータ・ブロック数は、1/8まで少なくなりました。
1ブロックが8倍の容量に増えたので、計算通りですね。
インデックスは「患者ID」「漢字氏名」「カナ氏名」「生年月日」「血液型」を用意しました。
Index unique On patientId [ PrimaryKey ];
Index idxNm On 漢字氏名;
Index idxKana On カナ氏名;
Index idxBirth On 生年月日;
Index idxBlood On (ABO血液型, RH血液型);諸々の準備ができたので、検証を開始しましょう。
Dグローバルをループさせる
データ・グローバル(Dグローバル)を単純にループする処理を作成し、両データベースの処理速度を比較します。
【検証PG】
ClassMethod LoopTest()
{
s rowId=""
f { s rowId = $o(^developer.data.Defrag1D(rowId), 1, data) q:rowId=""
s $lg(,,,,,,,,,,,ptnId,name,kanaNm,,,,sex,,,,,abo,rh,) = data
}
}【検証結果】
| 項目 | 1回 | 2回 | 3回 | 4回 | 5回 | 6回 | 7回 | 8回 | 9回 | 10回 | 平均 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 8KB | 7.71 | 7.08 | 6.94 | 6.98 | 6.80 | 6.58 | 6.88 | 6.76 | 7.04 | 6.82 | 6.96 |
| 64KB | 3.00 | 2.71 | 2.91 | 2.54 | 2.92 | 2.62 | 3.09 | 2.73 | 2.49 | 3.03 | 2.80 |
単純に処理速度も8倍になる・・・わけではありませんが、3倍近くの処理速度は出ているのが確認できます。
SQLでの処理速度を比較する
Dグローバルのループ速度を比較したので、次はSQLの処理速度を比較します。
検証項目は下記3つで行います。
各項目のクエリは、特に複雑に組んではいませんが、where節ではよく使用される検索方法と考えています。
では、検証を開始しましょう。
① 名称を検索する
名称を検索します。
検索結果はレコード全体の41%がHITする内容になります。
【検証PG】
ClassMethod SQLTest(name As %String, kana As %String)
{
s start = $zh
s cnt=0
&sql(
declare C200 cursor for
select patientId,漢字氏名,カナ氏名,性別,ABO血液型,RH血液型
into:ptnId,name,kanaNm,sex,abo,rh
from developer_data.Defrag1
where 漢字氏名 like :name or カナ氏名 like :kana
)
&sql(open C200)
for {
&sql(fetch C200)
if (SQLCODE=100) { quit }
s cnt = cnt + 1
}
&sql(close C200)
s time = $zh-start
s $li(^ZzTime, *+1)=time
s ^ZzRowCnt=cnt
}【検証結果】
| 項目 | 1回 | 2回 | 3回 | 4回 | 5回 | 6回 | 7回 | 8回 | 9回 | 10回 | 平均 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 8KB | 10.8 | 10.4 | 12.2 | 12.8 | 12.2 | 13.0 | 13.7 | 12.5 | 13.8 | 12.5 | 12.4 |
| 64KB | 7.8 | 6.7 | 6.6 | 7.2 | 6.5 | 6.8 | 6.8 | 6.0 | 6.8 | 7.0 | 6.8 |
同じ条件ですが、64KBのデータベースは2倍の速度で処理が完了している事が確認できます。
② 生年月日を範囲検索する
生年月日を範囲検索します。
検索結果はレコード全体の89%がHITする内容になります。
【検証PG】
ClassMethod SQLTest2(from As %Date, to As %Date)
{
s start = $zh
s cnt=0
&sql(
declare C200 cursor for
select patientId,漢字氏名,カナ氏名,性別,ABO血液型,RH血液型
into:ptnId,name,kanaNm,sex,abo,rh
from developer_data.Defrag1
where 生年月日 between :from and :to
)
&sql(open C200)
for {
&sql(fetch C200)
if (SQLCODE=100) { quit }
s cnt = cnt + 1
}
&sql(close C200)
s time = $zh-start
s $li(^ZzTime, *+1)=time
s ^ZzRowCnt=cnt
}【検証結果】
| 項目 | 1回 | 2回 | 3回 | 4回 | 5回 | 6回 | 7回 | 8回 | 9回 | 10回 | 平均 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 8KB | 13.9 | 15.1 | 15.9 | 15.2 | 16.9 | 15.3 | 15.0 | 17.3 | 15.5 | 9.9 | 15.0 |
| 64KB | 8.1 | 7.4 | 7.8 | 9.3 | 8.0 | 8.5 | 7.3 | 7.7 | 8.1 | 6.8 | 7.9 |
こちらも結果はあまり変わらず、64KBの方が2倍処理が早くなっています。
③ 血液型を検索する
血液型を検索します。
複合インデックスになります。
検索結果はレコード全体の12%がHITする内容になります。
【検証PG】
ClassMethod SQLTest3(abo As %Date, rh As %Date)
{
s start = $zh
s cnt=0
&sql(
declare C200 cursor for
select patientId,漢字氏名,カナ氏名,性別,ABO血液型,RH血液型
into:ptnId,name,kanaNm,sex,abo,rh
from developer_data.Defrag1
where ABO血液型 = :abo & RH血液型 = :rh
)
&sql(open C200)
for {
&sql(fetch C200)
if (SQLCODE=100) { quit }
s cnt = cnt + 1
}
&sql(close C200)
s time = $zh-start
s $li(^ZzTime, *+1)=time
s ^ZzRowCnt=cnt
}【検証結果】
| 項目 | 1回 | 2回 | 3回 | 4回 | 5回 | 6回 | 7回 | 8回 | 9回 | 10回 | 平均 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 8KB | 9.8 | 10.0 | 7.8 | 8.2 | 7.4 | 8.4 | 8.0 | 7.8 | 8.0 | 7.0 | 8.2 |
| 64KB | 2.9 | 3.3 | 2.8 | 3.3 | 3.1 | 2.9 | 2.7 | 3.1 | 3.5 | 2.6 | 3.0 |
やはり64KBの方が早く、2倍以上の速度で処理が完了しています。
まとめ
Dグローバルを単純にループする場合もSQLでの検索でも、処理速度に差がでる事が確認できました。
全てのグローバルで同様の結果がでるとは限りませんが、グローバルの構成と使用用途を限定すれば、高い効果が見込める設定ではないかと思います。
おわりに
これまでの結果をまとめると下記になります。
大量データの検索を行うテーブルに対しては、かなり有効な設定ではないかと思います。
また、ドキュメントには、ストリーム・データにも向いていると記載があります。
新しくシステムを構築する際、これらの設定も考慮に入れてみてはいかがでしょうか。
以上、データ・ブロックの設定によるループ処理の処理速度向上について解説しました。
本記事が、皆さまの実務や学びの中で、少し

