


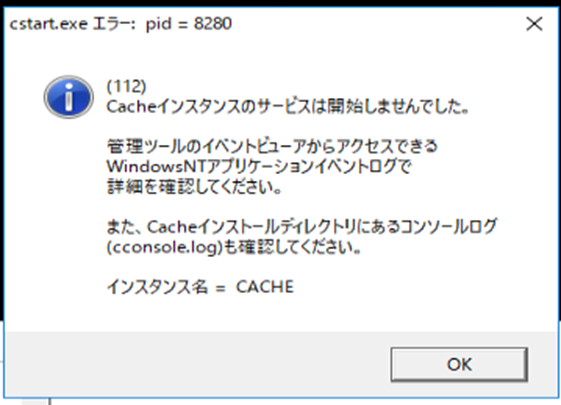
内部でエラーが発生し、インスタンスが起動しない時のトラブルシューティングです。
もしインスタンスがエラーで起動しない時は、この記事を一読してみて下さい。
解決の糸口になれば幸いです。
はじめに
この記事では、下記2つの事例に沿って解決方法をご紹介します。
※他の事例に遭遇したら、都度追記していきます。
システム部分でエラーを確認したら、兎にも角にもログファイル(IRIS=messages.log, cache=cconsole.log)を確認しましょう。
そこには、解決するための何らかのメッセージが記載されています。
.WIJファイルに異常が派生したケース
ログファイルを確認すると、下記表示が記載されています。
また、「MISMATCH.WIJ file」とも記載されています。
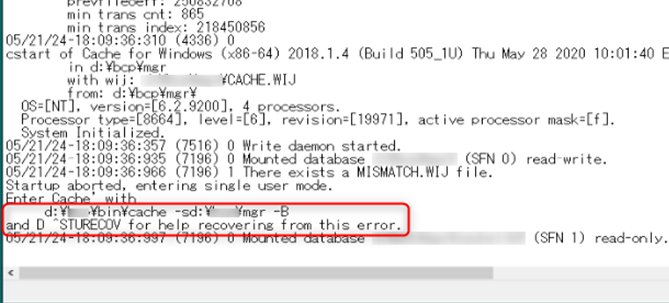
上記赤枠部分は、コマンドプロンプトを起動し2つのコマンドを実行し、状況の改善を試みろと記載しています。
先ずは、コマンドプロンプトにて下記コマンドを実行し、コマンドプロンプトからIRIS(Cache)へ接続を行いましょう。
コマンド実行後、いつもの見慣れたターミナル表示になります。
d:\[インストールディレクトリ]\bin\cache -sd:\[インストールディレクトリ]\mgr -Bd:\[インストールディレクトリ]\bin\irisdb -s[インストールディレクトリ]\mgr -BIRIS(Cache)接続後は、通常のターミナルと同様のコマンドが実行可能です。
ログインが必要であれば、併せて行って下さい。
下記サンプル画面は、ログインとコマンド「D ^STURECOV」を実行した直後の画面になります。
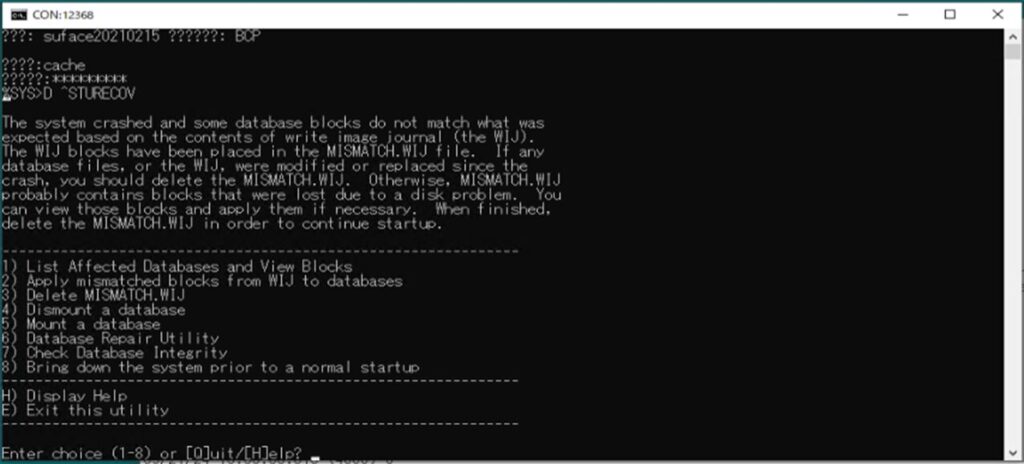
表示されている文面を下記に記載します。
The system crashed and some database blocks do not match what was expected based on the contents of write image journal (the WIJ).
The WIJ blocks have been placed in the MISMATCH.WIJ file.
If any database files, or the WIJ, were modified or replaced since the crash, you should delete the MISMATCH.WIJ.
Otherwise, MISMATCH.WIJ probably contains blocks that were lost due to a disk problem.
You can view those blocks and apply them if necessary.
When finished, delete the MISMATCH.WIJ in order to continue startup.
システムがクラッシュし、一部のデータベース ブロックが書き込みイメージ ジャーナル (WIJ) の内容に基づいて予測されたものと一致しません。
WIJ ブロックは MISMATCH.WIJ ファイルに配置されています。
クラッシュ以降にデータベース ファイルまたは WIJ が変更または置換された場合は、MISMATCH.WIJ を削除する必要があります。
それ以外の場合は、MISMATCH.WIJ にディスクの問題により失われたブロックが含まれている可能性があります。
これらのブロックを表示し、必要に応じて適用できます。
終了したら、起動を続行するために MISMATCH.WIJ を削除してください。
データベースとWIJファイルに相違が発生している旨と、この問題を解決するには、WIJファイルの削除が必要と記載されています。
正常に復旧を目指すのであれば、諸々手続きが必要ですが、今回はデータの保全より早期復旧を目指します。
コマンドプロンプトより、「3) Delete MISMATCH.WIJ」を選択し、WIJファイルを削除しましょう。
WIJファイル削除後、コマンドプロンプトに以下の確認メッセージが表示されます。
- Do you want to broadcast a message to anyone? No =>
(メッセージを誰かにブロードキャストしますか?) - Do you want to see the Cache status report? No =>
(キャッシュ ステータス レポートを表示しますか?) - Do you want to run the user defined shutdown routine? Yes =>
(ユーザー定義のシャットダウン ルーチンを実行しますか?) - Are you ready for the system to halt? Yes =>
(システムを停止する準備はできていますか?)
特に無ければ、「Enter」4回で問題ありません。
インスタンスは静かにシャットダウンします。
その後、高確立で各データベースにロックファイル(.lck)が残存しています。
→残存の程度は、クラッシュした部位やタイミングによります。
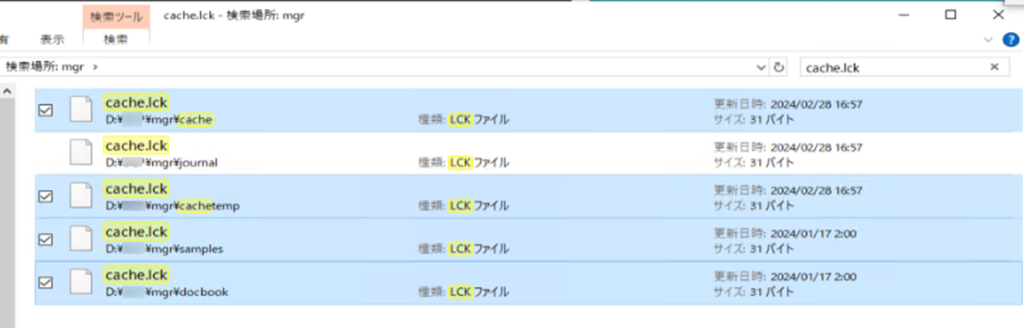
これらは、データベースのロックファイルは、インスタンスの起動に邪魔しかならないので、削除します。
以上で復旧作業が完了となります。
稀にエラーが複合しているケースがあり、再起動後に別のエラーで再度システムが起動しない事がありますが、同様にログファイルを確認して対応して下さい。
.WIJファイルに以上が発生したケース(別バージョン)
ログファイルを確認すると、下記表示が記載されています。
「WIJ file does not match expectations(WIJ ファイルは期待と一致しません)」
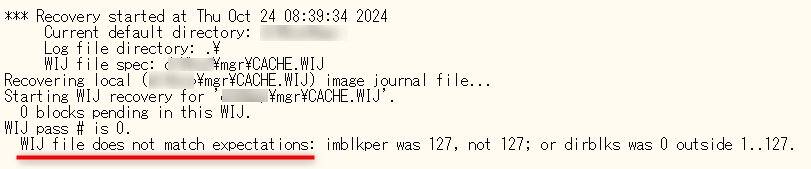
何らかの原因で、WJIファイルの整合性が取れなくなっています。
一先ず復旧を優先したいので、WIJファイルをリネームします。
リネーム後は再起動を行います。
WIJファイルのエラーは回避でき、新規WIJファイルが作成されます。
ただ、大体ジャーナルにも異常が発生しているため、「ジャーナルに異常が派生したケース」を別途参照して下さい。
ジャーナルに異常が派生したケース
ログファイルを確認すると、下記表示が記載されています。
※先ほどのケースと同じコマンドになります
また「errors during journal restore」と記載されています。

作業の流れは、[コマンドプロンプト] > [接続] > 「D ^STURECOV」まで同じ流れになります。
同じコマンドを実行しますが、今回のケースはジャーナルのエラーなので、ジャーナルのリカバリーオプションが表示されています。
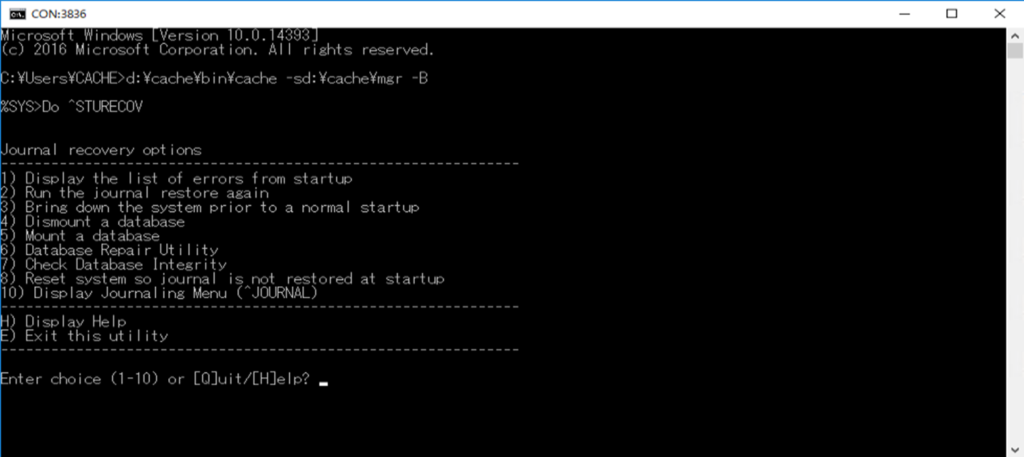
今回も復旧を優先します。
「8) Reset system so journal is not restored at startup」を選択して下さい。
選択後、コマンドプロンプト上に下記メッセージが表示されます。
If you erase this information then journal restore and transaction rollback will not occur when the system is brought up in multi-user mode.
Use this if you are going to restore the journal manually after users are allowed on the system.
The console log will contain the current journal file name and the position in the journal file to start the restore (the number preceding the journal file name).
Are you sure you want to do this?
この情報を消去すると、システムがマルチユーザー モードで起動されたときに、ジャーナルの復元とトランザクションのロールバックは行われません。
ユーザーがシステムにアクセスできるようにした後で、ジャーナルを手動で復元する場合は、これを使用します。
コンソール ログには、現在のジャーナル ファイル名と、復元を開始するジャーナル ファイル内の位置 (ジャーナル ファイル名の前の番号) が含まれます。
本当にこれを実行しますか?
とりあえず「Y」を入力します。
コマンド実行後は、cacheが起動したままの状態であるため、コマンドを使って強制的にシャットダウンを行います。
強制シャットダウンについては、下記記事を参照してください。

強制シャットダウン後の流れは、ロックファイルの残存を確認しておきます。
残存していれば削除を行って下さい。
ジャーナルに異常が発生 with DB破損版
DBが破損し、それに巻き込まれる形でジャーナルに異常が発生したケースになります。
ただし、最終的にDBが破損した事が判明しただけで、表向き(cconsole.log)的にはジャーナルの異常にしか見えませんでした。
状況的には、Cacheを起動したらそのままタイムアウトエラーが発生し、中途半端な起動になっています。
cconsole.logを確認すると、下記Journalのエラーがズラーっと表示されていました。
11/22/24-19:02:26:801 (6200) 0 Journal restore progress.
File: d:\bcp\mgr\journal\20241106.001 Address: 410120...(repeated 2 times)
11/22/24-19:12:26:829 (6200) 0 Journal restore progress.
File: d:\bcp\mgr\journal\20241106.001 Address: 410120...(repeated 2 times)
11/22/24-19:21:51:325 (5772) 1 Operating System shutdown! Cache performing fast shutdown.
11/22/24-19:22:17:408 (6844) 0 Shutting down Cach色々試しましたが、何一つ解決の糸口にならなかったです。
結局、解決には下記記事を参照する事になりました。
何とかcacheが起動し、ターミナルから「d ^INTEGRIT」を実行すると、DBが破損している事実が判明しました。
こんな解決方法もあるんだなと、目からうろこが落ちた日でした。
.idsファイルに不整合が発生したケース
レア中のレア現象になります。
インスタンス起動中に端末名称を変更した際に、稀に発生するエラーです。
そもそも端末名をコロコロ変更する事がないので、滅多に遭遇したことがありません。
また、IRISでは狙って操作しても発生した事を見たことがありません。
このエラーを見たら、超ラッキーかも!(笑
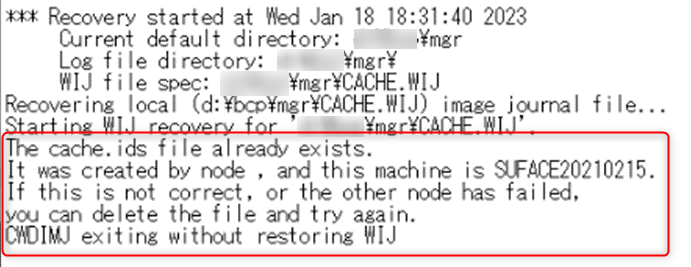
一先ずファイルを削除して再起動を行うように記載されているので、念のため.idsファイルをリネームして再起動を行います。
おわりに
IRIS/Cache共に、何かトラブルが発生したらログを確認するのは変わりません。
ログを確認した後、ログの記載に誘導されるままに復旧作業を行えば、大概は何とかなります。
他にもシステムエラーは体験しているので、まためぐり逢ったら追記していきたいと思います。
可能であれば、一生巡り合いたくないですね。

