


本記事は、作業キュー・マネージャ(%SYSTEM.WorkMgr.cls)について解説致します。
はじめに
ObjectScriptでは、シングルスレッドで処理されるロジックが多く見られますが、データ量の増加や処理時間の短縮が求められる現場では、並列処理の導入が効果的です。
並列処理といえば、JOBコマンドが代表的です。
バックグラウンドで別プロセスを起動できるため便利ですが、処理の終了通知や監視の仕組みを自前で用意する必要があり、本番環境での運用には手間がかかります。
そうした課題をスマートに解決してくれるのが「作業キュー・マネージャ(%SYSTEM.WorkMgr.cls)」です。
これを使えば、より簡単・確実に並列処理を実装することが可能になります。
本記事では、この作業キュー・マネージャを使ったシンプルかつ実用的な並列処理の実装方法について解説します。
概要
用語解説
作業キュー・マネージャの機能について、全体の構造をイメージ図にしました。
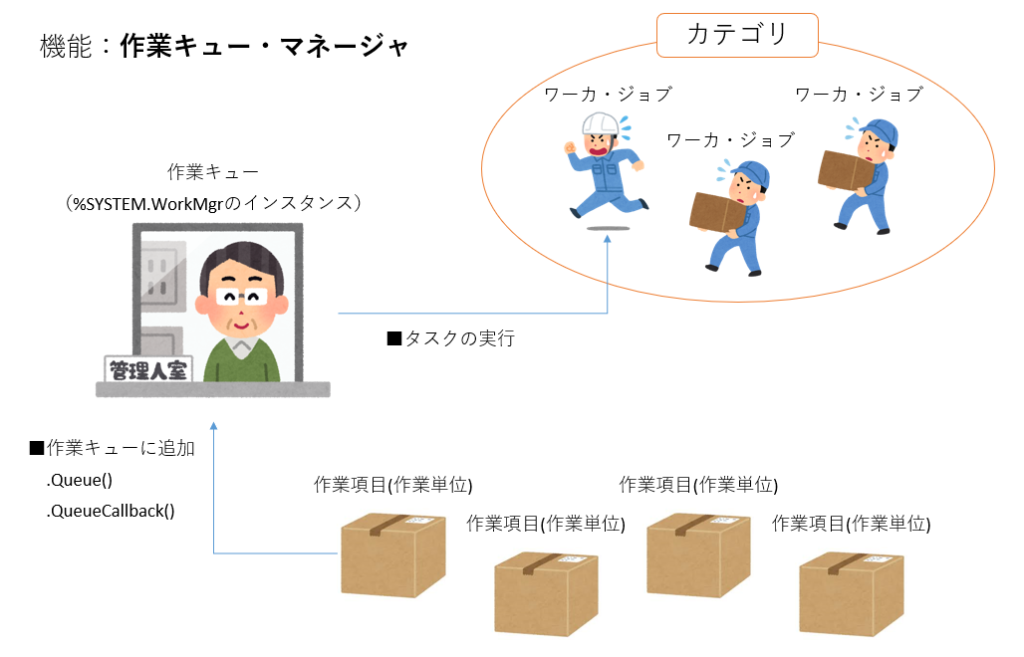
| 項目名 | 説明 |
|---|---|
| 作業キュー | %SYSTEM.WorkMgr.clsを%New()した時のインスタンス →$system.WorkMgrでもOK |
| ワーカ・ジョブ | 作業項目を実行するプロセス ※作業キューとは親子関係ではなく、独立した存在 |
| カテゴリ | ワーカ・ジョブのグループ 指定しないと「Default」のカテゴリが使用される |
| 作業項目 作業単位 | クラス・メソッドまたはサブ・ルーチン |
サンプルPG
作業キュー・マネージャのサンプルプログラムになります。
※一番ベーシックなコーディングです
ClassMethod main(time As %Integer = 10)
{
s workMgr = $system.WorkMgr.%New(,2)
w !,"全体開始:",$zdt($h,3,1)
f cnt = 1:1:6 {
d workMgr.Queue("..worker", cnt, time)
}
w !,"Queue完了:",$zdt($h,3,1)
d workMgr.Sync()
w !,"全体終了:",$zdt($h,3,1)
}
ClassMethod worker(cnt As %Integer, time As %Integer) As %Status
{
w !,"作業開始:",$j($j, 5), ", cnt:", $j(cnt,2), ", 時刻:",$zdt($h,3,1)
f pos=1:1:time { h 0.5 }
w " ~ ",$zdt($h,3,1)
q $$$OK
}ターミナルで実行した結果は下記になります。
全ての作業項目が完了した後に「全体終了」がwriteされているのが確認できます。
全体開始:2025-06-28 11:46:16
Queue完了:2025-06-28 11:46:16
作業開始: 3292, cnt: 1, 時刻:2025-06-28 11:46:16 ~ 2025-06-28 11:46:22
作業開始: 6868, cnt: 2, 時刻:2025-06-28 11:46:16 ~ 2025-06-28 11:46:22
作業開始: 3292, cnt: 3, 時刻:2025-06-28 11:46:22 ~ 2025-06-28 11:46:27
作業開始: 6868, cnt: 4, 時刻:2025-06-28 11:46:22 ~ 2025-06-28 11:46:27
作業開始: 3292, cnt: 5, 時刻:2025-06-28 11:46:27 ~ 2025-06-28 11:46:32
作業開始: 6868, cnt: 6, 時刻:2025-06-28 11:46:27 ~ 2025-06-28 11:46:32
全体終了:2025-06-28 11:46:32
作業項目(作業単位)
作業項目は、下記ルールに沿って作成する必要があります。
「同じ処理が同時に実行されたらどうなるか?」を常に意識してコーディングすることで、思わぬトラブルを未然に防ぐことができます。
PG解説
3つのステップで、並列処理の実装が可能です。
① 作業キューの作成
先ずは、「$SYSTEM.WOrkMgr.cls」をインスタンス化します。
第2引数は、ワーカ・ジョブ数の設定です。
今回は2つ用意しました。
第3引数はカテゴリの指定で、今回は初期値の「Default」にしています。
s workMgr = $system.WorkMgr.%New(,2)② 作業キューに作業項目を追加
①で作成した作業キューに作業項目を追加します。
他クラスのメソッドであれば「”##class(developer.parallel.Sample).child”」を指定します。
今回追加した6つの作業キューは、全て同じ関数「child」ですが、
第2引数以降は、クラス・メソッドに対する引数です。
引数の数に合わせて設定します。
f cnt = 1:1:6 {
d workMgr.Queue("..child", cnt, time)
}③ 待つ
後は作業項目が全て処理されるのを待つだけです。
d workMgr.Sync()たったこれだけで、並列処理が作成できちゃいます。
簡単ですね。
今まで色々苦労してきたのが何だったのか!?ってレベルです。
プロセスを確認する
作業中のプロセスを確認してみたいと思います。
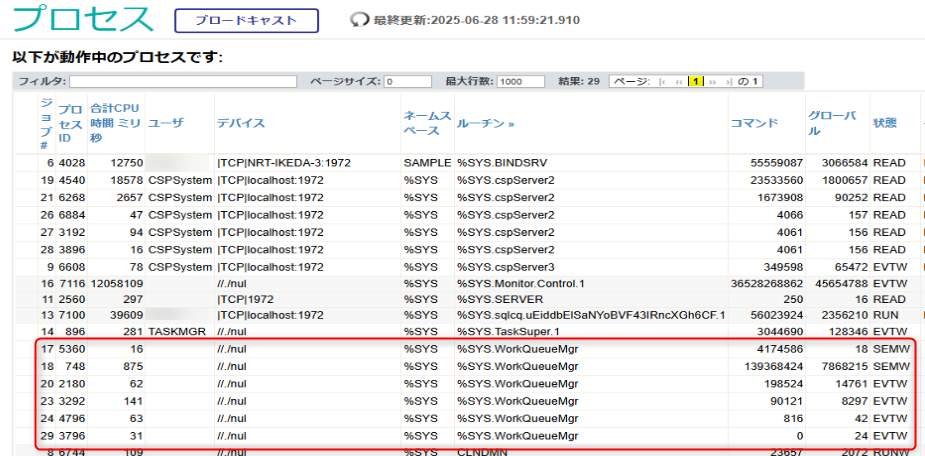
管理ポータルより[システムオペレーション] > [プロセス]を選択すると、プロセス画面が起動します。
プロセス一覧の中で、ルーチン列の「%SYS.WOrkQueueMgr」を表記されているプロセスが、作業キュー・マネージャ関連のプロセスになります。
下記画像は、並列処理実行前の状態です。
では、並列処理を実行してみましょう。

プロセスID = 3292, 3796(赤枠)が、ワーカ・ジョブを動かしているプロセスです。
プロセスID = 6776(青枠)は、おそらく作業キューだと思います。
プロセス一覧を確認していると、ワーカ・ジョブ用に常に常駐しているプロセスがいて、いざ作業となった時に待機しているリソースを使用しているようです。
※たまに新規プロセスを作成していたりします。
内部利用をを確認する
この作業キュー・マネージャは、使い勝手が良いため、ObjectScriptの内部処理で結構使われているようです。
では、用途の1つ「インデックスの再作成」で確認してみましょう。
インデックスの再作成処理実行中のプロセス一覧です。

プロセスID = 3292, 4796とかは、先ほど確認した常駐プロセスにいましたね。
また、インデックスの再作成中に停止させると、「%SYS.WorkQueueMgr」が表示されます。
レコードIDを分割して実行しているのでしょうか。
処理時間を短縮させようとする意気込みが伝わってきます。

ObjectScriptの内部でガッツリ使用しているのを確認すれば、信頼度は高まりますね!
作業項目のwriteコマンドについて
作業項目でのwriteコマンドは、即座にターミナルに反映されません。
作業項目で実行されたwriteコマンドは、作業キューのバッファに一時的に蓄えられ、待機系関数(Sync等)実行時に出力されます。
先ずは、動作を確認してみましょう。
ClassMethod main(time As %Integer = 10)
{
s workMgr = $system.WorkMgr.%New(,2)
w !,"全体開始:",$zdt($h,3,1)
f cnt = 1:1:6 {
d workMgr.Queue("..worker", cnt, time)
}
h 30
w !,"Sync直前:",$zdt($h,3,1)
d workMgr.Sync()
w !,"全体終了:",$zdt($h,3,1)
}
ClassMethod worker(cnt As %Integer, time As %Integer) As %Status
{
w !,"作業開始:",$j($j, 5), ", cnt:", $j(cnt,2), ", 時刻:",$zdt($h,3,1)
f pos=1:1:time { h 0.5 }
w " ~ ",$zdt($h,3,1)
q $$$OK
}実行した結果は下記になります。
「Sync直前」で出力した日時より、作業項目で出力した日時の方が「前」になっていますが、出力した順序は「後」になっています。
全体開始:2025-06-28 18:13:24
Sync直前:2025-06-28 18:13:54
作業開始: 1088, cnt: 2, 時刻:2025-06-28 18:13:24 ~ 2025-06-28 18:13:29
作業開始: 6940, cnt: 1, 時刻:2025-06-28 18:13:24 ~ 2025-06-28 18:13:29
作業開始: 1088, cnt: 3, 時刻:2025-06-28 18:13:29 ~ 2025-06-28 18:13:34
作業開始: 6940, cnt: 4, 時刻:2025-06-28 18:13:29 ~ 2025-06-28 18:13:34
作業開始: 1088, cnt: 6, 時刻:2025-06-28 18:13:34 ~ 2025-06-28 18:13:39
作業開始: 6940, cnt: 5, 時刻:2025-06-28 18:13:34 ~ 2025-06-28 18:13:39
全体終了:2025-06-28 18:13:54
また、作業項目のwriteコマンドの出力が、作業項目単位になっている事に注目です。
通常であれば、各ワーカ・ジョブのwriteコマンド「作業開始:…」が先に出力されるはずですよね。
では、この出力を少しだけ制御をしてみましょう。
Flush()
使用する関数は「Flush」になります。
待機系関数(Sync等)実行時に出力する仕様は変わりませんが、関数「Flush」を実行したタイミング順に出力されます。
ClassMethod worker(cnt As %Integer, time As %Integer) As %Status
{
w !,"作業開始:",$j($j, 5), ", cnt:", $j(cnt,2), ", 時刻:",$zdt($h,3,1)
d $system.WorkMgr.Flush()
f pos=1:1:time { h 0.5 }
w !,"作業終了:",$j($j, 5), ", cnt:", $j(cnt,2), ", 時刻:",$zdt($h,3,1)
q $$$OK
}実行した結果は下記になります。
全体開始:2025-06-28 18:31:59
Sync直前:2025-06-28 18:32:29
作業開始: 3836, cnt: 1, 時刻:2025-06-28 18:31:59
作業開始: 4816, cnt: 2, 時刻:2025-06-28 18:31:59
作業終了: 3836, cnt: 1, 時刻:2025-06-28 18:32:04
作業終了: 4816, cnt: 2, 時刻:2025-06-28 18:32:04
作業開始: 3836, cnt: 3, 時刻:2025-06-28 18:32:04
作業開始: 4816, cnt: 4, 時刻:2025-06-28 18:32:04
作業終了: 3836, cnt: 3, 時刻:2025-06-28 18:32:10
作業終了: 4816, cnt: 4, 時刻:2025-06-28 18:32:10
作業開始: 3836, cnt: 5, 時刻:2025-06-28 18:32:10
作業開始: 4816, cnt: 6, 時刻:2025-06-28 18:32:10
作業終了: 3836, cnt: 5, 時刻:2025-06-28 18:32:15
作業終了: 4816, cnt: 6, 時刻:2025-06-28 18:32:15
全体終了:2025-06-28 18:32:29
いつも通りの出力になりました。
何となく安心感がでます(笑
writeコマンドの制御を行いたい場合は「Flush」を使用してください。
速度比較を行う
念のため、並列処理の効果を確認してみます。
この2つの条件で、2,000万件の患者レコードから、指定条件の患者数をカウントしたいと思います。
SQLの処理
SQLでの検索処理のサンプルです
何の変哲もないSQLのクエリです。
select count(*)は行わず、ループより件数を取得しています。
ClassMethod testSpeed(name As %String = "", kana As %String = "", birthDay As %Integer = "")
{
s start = $zh
s stm = ##class(%SQL.Statement).%New()
k query, arg
s query(1) = "select patientId,漢字氏名,カナ氏名,生年月日,性別"
, query(2) = "from developer_data.Defrag1"
s (where, dlm) = ""
s:(name '= "") where = where_dlm_"漢字氏名 like ?", dlm = " & ", arg($i(arg)) = "%"_name_"%"
s:(kana '= "") where = where_dlm_"カナ氏名 like ?", dlm = " & ", arg($i(arg)) = "%"_kana_"%"
s:(birthDay '= "") where = where_dlm_"生年月日 > ?" , dlm = " & ", arg($i(arg)) = $zdh(birthDay,3)
s query(3) = "where "_where
s query = 3
s cnt = 0
s rset = stm.%ExecDirect(, .query, arg...)
while ( rset.%Next() ){
s cnt = cnt + 1
}
s time = $zh - start
s $li(^ZzTime, *+1)=time
}並列処理
並列処理のサンプルになります。
ワーカ・ジョブを4つ用意し、500万件毎に区切って検索を行っています。
ClassMethod testSpeedPara(name As %String = "", kana As %String = "", birthDay As %String = "")
{
s s = $zh
k ^parallel
s workMgr = $system.WorkMgr.%New(,4)
s date = $zdh(birthDay,3)
s add = 5000000
, start = 1
, end = add
f cnt = 1:1:4 {
d workMgr.Queue("..paraWork", cnt, start, end, name, kana, date)
s start = 1 + end
, end = end + add
}
d workMgr.Sync()
s cnt = 0
f pos = 1:1:4 { s cnt = cnt + $g(^parallel(pos)) }
s time = $zh - s
s $li(^ZzTime, *+1)=time
}
ClassMethod paraWork(pos As %Integer, startId As %Integer, endId As %Integer, name As %String, kana As %String, birthDay As %Date) As %Status
{
s cnt = 0
f id=startId:1:endId {
s $lg(,,,,,,,,,,,patientId,漢字氏名,カナ氏名,,,,性別,生年月日,,,,,) = ^developer.data.Defrag1D(id)
i ((name="")||(漢字氏名[name))&&
((kana="")||(カナ氏名[kana))&&
((birthDay="")||(生年月日>birthDay)) {
s cnt = cnt + 1
}
}
s ^parallel(pos) = cnt
q $$$OK
}結果
実行結果になります。
| 項目 | 1回 | 2回 | 3回 | 4回 | 5回 | 6回 | 7回 | 8回 | 9回 | 10回 | 平均 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| SQL | 71.9 | 72.5 | 69.2 | 76.3 | 71.5 | 70.3 | 70.9 | 80.3 | 73.6 | 67.7 | 72.43 |
| 並列 | 46.6 | 47.5 | 48.8 | 47.5 | 46.8 | 46.3 | 47.5 | 47.3 | 46.8 | 47.9 | 47.29 |
ワーカ・ジョブの数にもよるとは思いますが、今回の検証ではSQLより並列処理の方が早かったです。
この結果を見ると、並列処理も悪くないですね。
CPU負荷
ワーカ・ジョブ4つ使用しているので、CPU負荷も相応に上昇しているはずです。
確認してみましょう
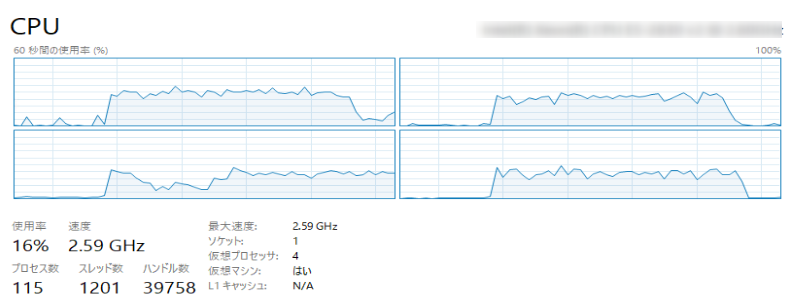
並列処理時のCPU負荷
並列処理では、だいたいMAX46%くらいまで上昇しています。
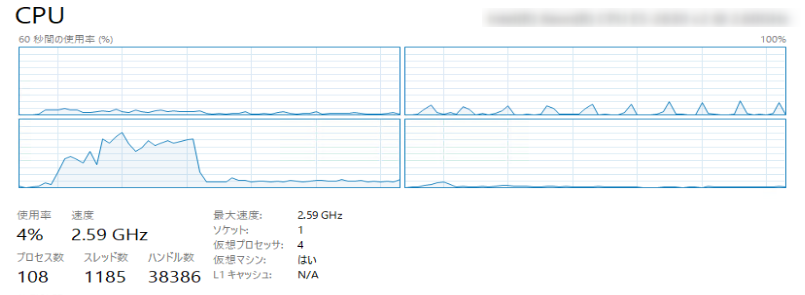
SQLのCPU負荷
SQLでは、MAX11%程のCPU負荷になっています。
処理速度を採用するか、CPU負荷を採用するか・・・悩みますね。
実装する際は、要検討をお願いします。
おわりに
いかがだったでしょうか。
本記事は、下記内容について触れました。
並列処理は、業務処理のボトルネックを解消する強力な手段です。
しかし、「導入が面倒そう」「失敗時の制御が難しい」と感じて敬遠されがちでもあります。
今回紹介した「%SYSTEM.WorkMgr」を使えば、そうしたハードルを下げつつ、堅牢な並列処理を手軽に実現できます。
日々のバッチ処理やデータ変換処理などに、ぜひ一度取り入れてみてください。
次回は、作業キュー・マネージャのカスタマイズについて記事にしたいと思います。

