


本記事は、テストデータを作成する%Populateについての紹介第2回目です。
前回初級編から引き続きマニアック編をお送りいたします。
はじめに
テストデータは、単にランダムに生成しても実用性が低いです。
さらに、データクラスは単純なデータ型にとどまらず、配列やリスト、リレーションなど、複雑な構成を持つ場合も少なくありません。
そのような複雑なデータクラスに対しても、%Populateを使用すればテストデータを生成することが可能です。
本記事では、初級編で取り上げなかった複雑なデータ構造に対し、具体的にどのような設定を行うべきかを詳しく紹介します。
【%Populate初級編】

特殊なデータ型のデータ生成
データクラスが、%String型や%Integer型等のシンプルなデータ型で構成されていれば、特に悩む必要はありませんが、中には複雑な構成のデータクラス等があります。
そのような複雑なデータ構造でも、%Populateでテストデータを作成する事が可能です。
以下は、特殊なデータ型に対する対応方法の解説になります。
シリアル型
シリアル型のデータクラスも、%Populateを継承していないとデータの生成が行われません。
下記サンプルは、シリアル型のプロパティを3種用意しました。
【メインのデータクラス】
Class developer.data.Sample Extends (%Persistent, %Populate)
{
Index idx On code [ PrimaryKey ];
Property code As %String;
Property name As %String;
/// シリアル型単品
Property sObj As developer.data.Test2;
/// シリアル型複数その1
Property sObjs1 As list Of developer.data.Test2;
/// シリアル型複数その2
Property sObjs2 As array Of developer.data.Test2;
}【シリアル型のデータクラス】
Class developer.data.Test2 Extends (%SerialObject, %Populate)
{
Property Child1 As %String;
Property Child2 As %Integer;
}
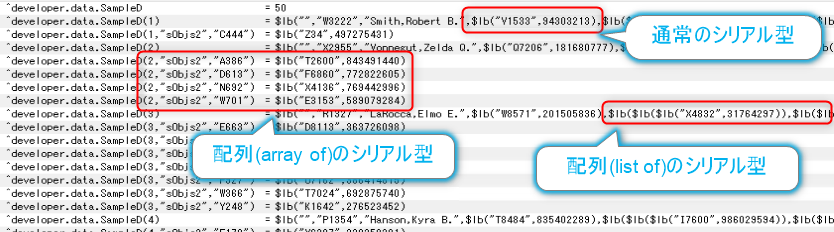
関数「Populate(50)」でデータを生成します。
ランダムな値のデータですが、シリアル型として生成されている事が分ります。
リレーション
リレーションの親子関係も、双方に%Populateを継承する必要があります。
下記サンプルは親と子が1:多になる設定のリレーションになります。
【親データクラス】
Class developer.data.Sample Extends (%Persistent, %Populate)
{
Index idx On code [ PrimaryKey ];
Property code As %String;
Property name As %String;
Relationship rObj As developer.data.Test1 [ Cardinality = children, Inverse = Child1 ];
}【子データクラス】
Class developer.data.Test1 Extends (%Persistent, %Populate)
{
Relationship Child1 As developer.data.Sample [ Cardinality = parent, Inverse = rObj ];
Property Child2 As %Integer;
}下記コマンドを実行し、データの生成を行います。
※親データ作成後にリレーションの子も生成します。
w ##class(developer.data.Sample).Populate(50)
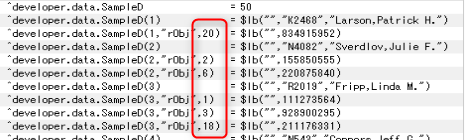
w ##class(developer.data.Test1).Populate(50)データを確認します。
リレーションの子がランダムに親と紐づいている事が確認できます。
※子のデータ作成は、親より多い方が良いです。子が紐づかないケースが発生します。
データクラス型
プロパティのデータ型が、他のデータクラスになっているタイプです。
プロパティの値は、レコードIDになります。
下記サンプルは、プロパティの型が「developer.data.Test3.cls」を設定しています。
【メインデータクラス】
Class developer.data.Sample Extends (%Persistent, %Populate)
{
Index idx On code [ PrimaryKey ];
Property code As %String;
Property name As %String;
/// 型がデータクラス = レコードIDが格納される
Property oObj as developer.data.Test3;
}【型となるデータクラス(以降、型クラスと呼称)】
Class developer.data.Test3 Extends (%Persistent, %Populate)
{
Property Child1 As %String;
Property Child2 As %Integer;
}下記コマンドを実行し、データの生成を行います。
※先に型となるデータクラスから生成します。
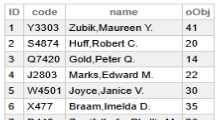
w ##class(developer.data.Test3).Populate(50)
w ##class(developer.data.Sample).Populate(50)データを確認すると、データクラス「Test3」より、ランダムなレコードIDが格納されている事が確認できます。
OnPopulate
関数「OnPopulate」を設定する事で、生成されたデータをより詳細に制御する事が可能です。
この関数は、objectが保存される前に実行されます。
これにより、生成されたデータに対して追加の制御が可能となります。
サンプルです。
Class developer.data.Sample Extends (%Persistent, %Populate)
{
Index idxTxt On Text(KEYS) [ Type = bitmap ];
Property name As %String(POPORDER = 1, POPSPEC = "ValueList("",藤原道長,紫式部,源倫子,一条天皇"")");
Property List As %List;
Property Text As %Text(COLLATION = "SQLSTRING", LANGUAGECLASS = "%Text.Japanese", MAXLEN = 36000);
Method OnPopulate() As %Status
{
s sts = $$$OK
try {
s ..List = $case(i%name,
"藤原道長":$lb("藤原頼通","藤原教通"),
"紫式部":$lb("大弐三位"),
"源倫子":$lb("彰子","妍子"),
"一条天皇":$lb("後一条天皇","敦康親王"),
:"")
s ..Text = $case(i%name,
"藤原道長":"藤原道長(966~1027年)は、平安時代中期の貴族で、摂関政治を極めた人物",
"紫式部":"紫式部(生没年不詳、10世紀後半~11世紀前半)は、平安時代中期の女性作家で、宮廷に仕えた貴族です。",
"源倫子":"源倫子(もとこ、964~1025年)は、平安時代中期の女性で、藤原道長の正室(正式な妻)として知られています。",
"一条天皇":"一条天皇(980~1011年)は、平安時代中期の天皇で、第66代天皇として986年から1011年まで在位しました。",
:"")
}catch e{
s sts = e.AsStatus()
}
q sts
}
}では、データを確認してみます。

関数「OnPopulate」では、Populateでは生成されないデータ型(%List, %Text, %Stream系, 等々)に対し、テストデータを作成するとよいでしょう。
後は、全体的にデータの最終的な調整を行えばよいと思います。
特殊ケースでのPOPSPECパラメータ設定方法
作成されるデータの指向を設定するパラメータ「POPSPEC」ですが、特殊なデータ型にも対応しています。
リスト・配列のPOPSPECパラメータ指定
リスト型のプロパティは、「実行関数:最大配列数」で指定します。
配列型のプロパティは、「実行関数:最大配列数:キー値設定関数」で指定します。
各設定値は省略可能で、初期値は「最大配列数=10」「キー値設定関数=String()」となっています。
サンプルです。
Class developer.data.Sample Extends (%Persistent, %Populate)
{
Property ID As list Of %String(POPSPEC = ".Sample():3");
Property name As array Of %String(POPSPEC = "##class(developer.data.Sample).GetName(""名前""):3:Integer()");
Method Sample() As %String
{
q $tr($j($r(1000),8)," ","0")
}
ClassMethod GetName(txt As %String) As %String
{
q "サンプル値:"_$r(1000)_txt
}
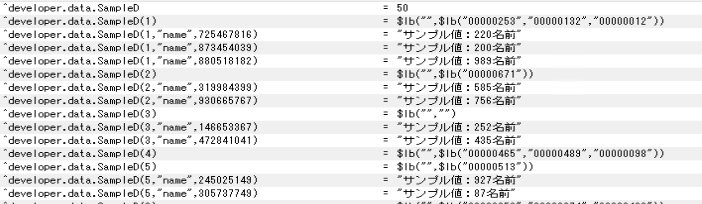
}データを作成しました。
各データとも、0~3(最大値)個のデータが作成されている事が分ります。
SQLを利用するPOPSPECパラメータ指定
SQLを実行してのデータ取得も行えます。
SQLでの取得設定は、データ型によって省略できる設定が異なります。
■データ型がリスト・配列
「:最大配列数:キー値設定関数:サンプル数:クエリテーブル:列名」
■データ型が上記以外
「:::サンプル数:クエリテーブル:列名」
→「最大配列数」「キー値設定関数」が不要のため省略します。
※サンプル数 = テーブルから取得するデータパターン数
サンプルです。
Class developer.data.Sample Extends (%Persistent, %Populate)
{
Property ID As %String(POPSPEC = ":::10:developer_csv.Patient:patientId");
Property name As list Of %String(POPSPEC = ":3::20:developer_csv.Patient:漢字氏名");
Property kanaName As array Of %String(POPSPEC = ":3:Integer():30:developer_csv.Patient:カナ氏名");
Method Sample() As %String
{
q $tr($j($r(1000),8)," ","0")
}
ClassMethod GetName(txt As %String) As %String
{
q "サンプル値:"_$r(1000)_txt
}
}データを作成しました。
他のテーブルからデータを取得し、レコードを生成しています。

関連するデータを設定する
「プロパティAとプロパティBは、コードと名称として互いに相関関係がある」
データクラスには、上記の様にプロパティ間でデータが関連しているケースが時折見受けられます。
例えば、日本で人物データを扱う場合、漢字名称に対しカナ名称が設定されている等は良くあります。
場合によっては、ローマ字名もデータとして設定があったりします。
しかし、Populateを利用してデータを作成する際、漢字名称とカナ名称が正しく対応付けられず、別人の名前になったりします。
今回は、これの相関のあるプロパティの不一致を解消しましょう。
ポイントは下記2点になります。
- POPORDERで、データ生成の順位付けを行う
- データ生成関数(Kana())で、対象プロパティの値「i%name」で分岐させる。
サンプルは下記になります。
Class developer.data.Sample Extends (%Persistent, %Populate)
{
/// 漢字名称
Property name As %String(POPORDER = 1, POPSPEC = "ValueList("",藤原道長,紫式部,源倫子,一条天皇"")");
/// カナ名称
Property kanaName As %String(POPORDER = 2, POPSPEC = ".Kana()");
Method Kana() As %String [ CodeMode = expression ]
{
$case(i%name,
"藤原道長":"フジワラミチナガ",
"紫式部":"ムラサキシキブ",
"源倫子":"ミナモトトモコ",
"一条天皇":"イチジョウテンノウ",
:"")
}
}「POPORDER=1」のプロパティ「name」が先にデータを格納します。
プロパティ「kanaName」は、その値に沿って格納する値を選択する事で、漢字氏名とカナ氏名の関連付けを行っています。

作成したデータは、漢字氏名とカナ氏名が一致していますね。
おわりに
いかがだったでしょうか。
全2回にわたり、%Populateの仕様や構築方法について解説しました。
%Populateを活用することで、複雑なデータ生成プロセスを効率化し、より高度なプログラム開発に集中できる環境が整います。
さらに、複雑なデータ構成にも柔軟に対応できる仕組みが備わっている点も大きな魅力です。
本記事でご紹介した内容を、ぜひ実際のプロジェクトやテスト環境で試し、ObjectScriptの可能性を最大限に引き出していただければ幸いです。

