


はじめに
クエリの実行速度を調査していた際、2つのクエリの速度差に違和感を覚え、原因を調査しましたた。
その際に、「並列クエリ」を学ぶ機会があり、今回の記事のネタにしました。
下記に該当する方を対象として解説を行いたいと思います。
並列クエリとは何か
その名の通り、「複数のプロセッサを搭載したのコンピュータシステム」環境で動作させている場合、1つのクエリを複数のプロセスで同時(並列)に実行する事を指します。
1つのクエリを分割して実行するので処理速度は向上しますが、引き換えにCPUの負荷が上昇します。
処理速度とCPU負荷のトレードオフですね。
ただし、並列クエリは全てのクエリが対象ではありません。
並列処理が出来るクエリ・出来ないクエリがあります。
また、自動的に並列クエリとしてクエリが実行されるケースと、任意の設定によって並列クエリを実行させるケースがあります。
今回は、ここら辺を深掘りしていこうかと思います。
並列クエリの自動設定
管理ポータル起動後、[システム管理] > [構成] > [SQLとオブジェクトの設定] > [SQL]を開きます。
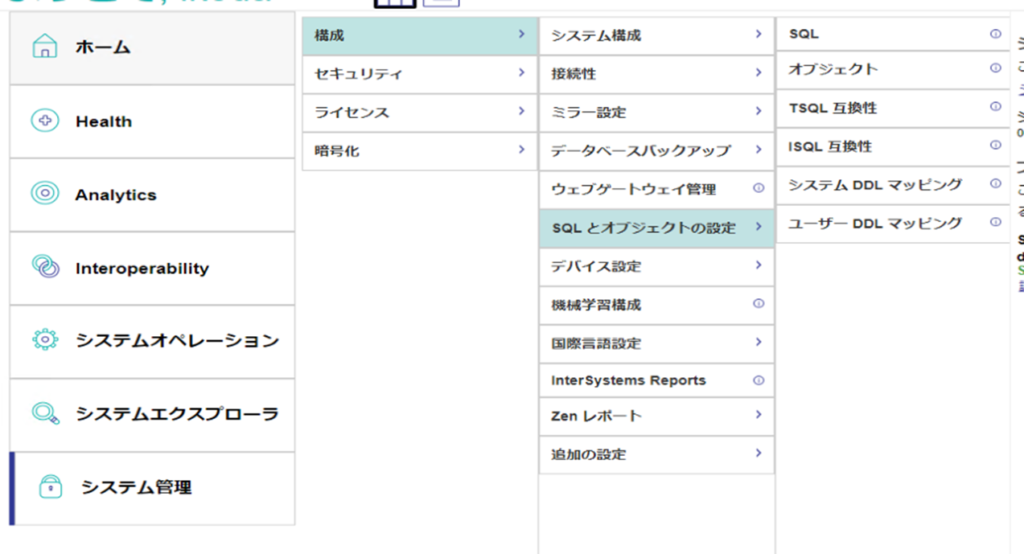
画面「SQL」で、「単一プロセス内でクエリを実行」にチェックが付いていない場合、SQLオプティマイザの判断によって、自動的に並列クエリが選択されます。
※この設定は、IRIS 2019.1より実施されています。
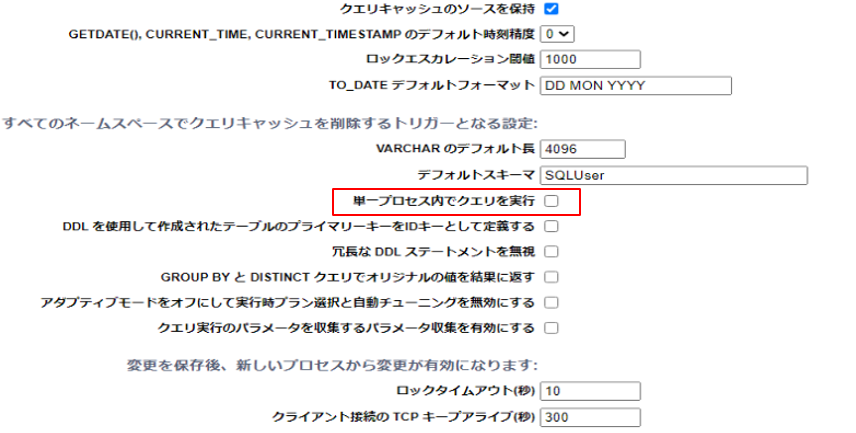
オプティマイザが「並列クエリで行くぞ!」と判断したクエリ
並列クエリの任意設定
並列クエリの自動設定を行っていても、全てのクエリに対し並列で実行するわけではありません。
大まかに下記条件に該当するクエリは、並列クエリの対象外となります。
一部抜粋。詳しくは下記参照
一先ず、並列クエリ対象外の条件が分かったので、次は任意で並列クエリを設定してみましょう。
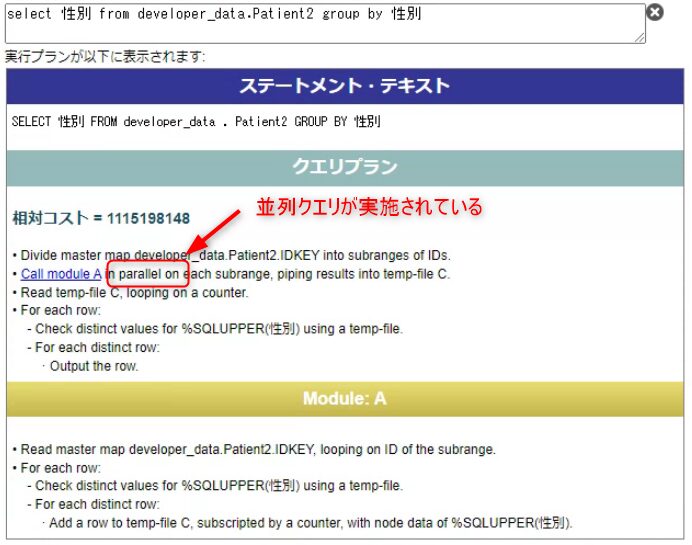
通常のクエリ ※参考比較用
先ずは、並列クエリが実行されないクエリのプランになります。
並列クエリ(%Parallelキーワード付与)
並列クエリを実行するには、FROM節の直後に「%Parallel」と記載します。
クエリプランを確認すると、「Call module A in parallel on each subrange, piping results into temp-file B.(各サブ範囲でモジュール A を並列に呼び出し、結果を一時ファイル B にパイプします。)」との一文が含まれています。
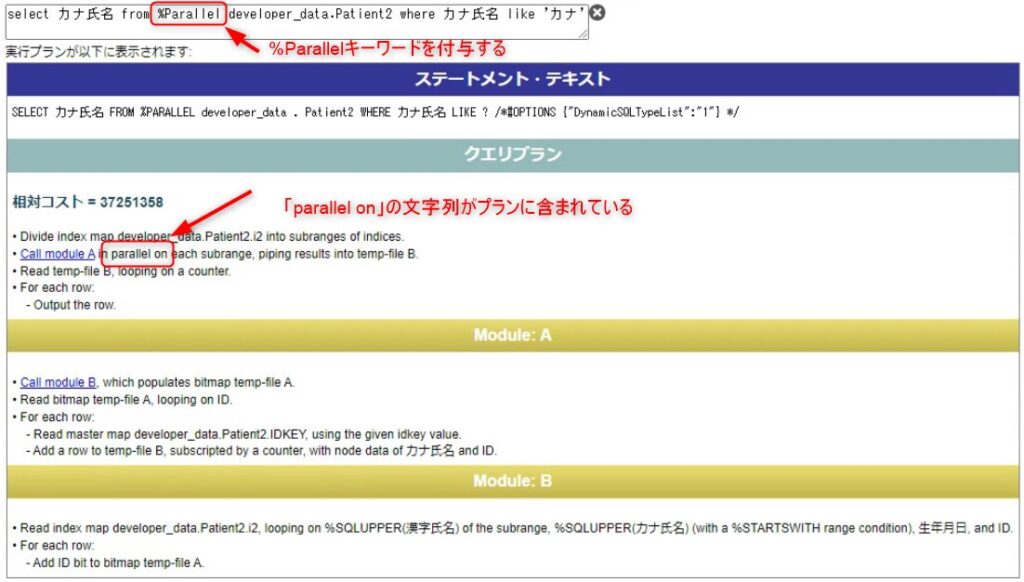
並列クエリ実行
下記結果は、先ほどのクエリを実行した時の処理速度を比較しています。
処理速度の比較だけで見ると、並列クエリを使った方が圧倒的にお勧めできる設定だと思います。
| 項目 | 1回 | 2回 | 3回 | 4回 | 5回 | 6回 | 7回 | 8回 | 9回 | 10回 | 平均 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 並列 | 30.17 | 31.93 | 31.30 | 32.01 | 31.68 | 32.21 | 30.50 | 31.77 | 31.93 | 31.63 | 31.51 |
| 通常 | 94.64 | 87.49 | 86.44 | 89.16 | 89.83 | 86.73 | 86.17 | 87.25 | 86.43 | 82.80 | 87.69 |
では、このときのCPUの負荷はどうなっているでしょうか。
タスクマネージャより、CPUの負荷を確認してみます。
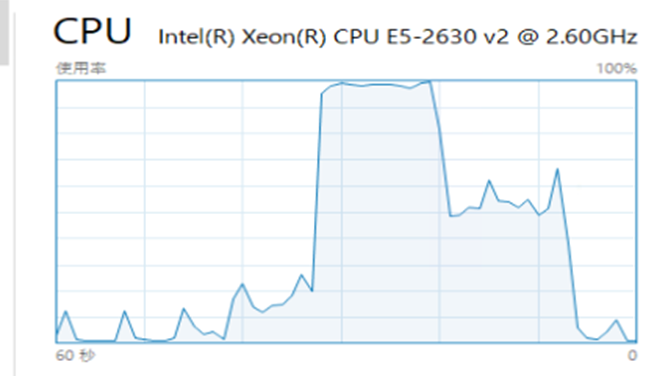
■並列クエリ時のCPU負荷
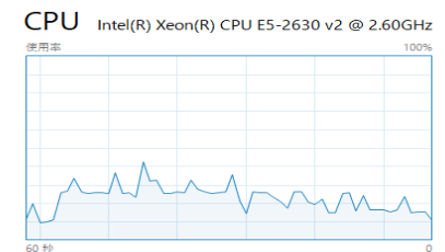
■通常時のCPU負荷
並列クエリを実行すると、天井を「ド衝く」勢いで高騰しているのが分かります。
その代わり、処理がすぐ終わっているのが確認出来ますね。
一方の通常のクエリでは、CPUの高騰こそないものの、処理の終了がかなり長い時間かかっているのが分かります。
つまり、その間ずっと1つのCPを占有していることになります。
CPU爆上げでの短期決戦か、CPUの上昇を抑えての長期決戦か・・・
両極端ですねぇ。
並列クエリで稼働させるプロセス数を制御できれば、並列クエリ一択かもしれません(笑
並列クエリを使いたくない時
並列クエリを何らかの理由で停止したい時の対応方法になります。
全体を根っこから停止させる方法と、個別に停止させる方法があります。
根っこから停止させる
管理ポータルの画面「SQL」で「単一プロセス内でクエリを実行」にチェックを入れる方法と、下記コマンドを使用することでも、システム全体での使用を停止する事が可能です。
// 1が既定値で「並列処理有効」
s sts = $SYSTEM.SQL.Util.SetOption("AutoParallel",0,.oldval)※いずれにしても「%Parallel」キーワードが付与されたクエリは止まりません。
設定値の確認を行うには、下記コマンドを実行します。
d $SYSTEM.SQL.CurrentSettings()実行結果は下記になります。
16行目「Enable auto hinting for %PARALLEL」が「0」になっている事が分かります。
SQL CONFIGURATION SETTINGS
SQL OPTIONS
Retain SQL as comments: 1
ECP sync for SELECT statements: 0 (Default)
Cached query save source flag: 1
Identifier translation from: ~ `!@#$%^&*()_+-=[]\{}|;':",./<>? (Default)
Identifier translation to: (Default)
Default time precision: 0 (Default)
TCP keep alive interval (in seconds): 300
All class queries project as stored procs: 0 (Default)
Lock escalation threshold: 1000 (Default)
Default schema: SQLUser (Default)
Support delimited identifiers: 1 (Default)
Allow extrinsic functions in SQL statements: 0 (Default)
Apply ANSI operator precedence : 1
Enable auto hinting for %PARALLEL : 0
Threshold of auto hinting for %PARALLEL : 3200 (Default)
Enable RTPC : 1 (Default)
Enable adaptive mode : 1 (Default)
Enable parameter sampling : 0 (Default)
Lock timeout: 10 (Default)
SQL security enabled: 1 (Default)
Perform referential integrity checks on
foreign keys for INSERT, UPDATE, and DELETE: 1 (Default)
ODBC VARCHAR Max Length: 4096 (Default)
TO_DATE() Default Format: DD MON YYYY (Default)
DDL OPTIONS
Allow DDL DROP of non-existent table or view: 0 (Default)
Allow DDL CREATE TABLE or CREATE VIEW
for existing table or view: 0 (Default)
Allow create primary key through DDL
when key exists: 0 (Default)
Allow DDL DROP of non-existent constraint: 0 (Default)
Allow DDL CREATE INDEX for existing index: 0 (Default)
Allow DDL DROP of non-existent index: 0 (Default)
Allow DDL ADD foreign key constraint
when foreign key exists: 0 (Default)
Does DDL DROP TABLE delete the table's data?: 1 (Default)
Are primary keys created through
DDL not ID keys: 1 (Default)
Are classes created via DDL
CREATE TABLE statement defined as Final: 1 (Default)
Do classes created by a DDL CREATE TABLE
statement use $Sequence for ID assignment: 1 (Default)
Do classes created by a DDL CREATE TABLE
statement define a bitmap extent index: 1 (Default)
SQL OPTIMIZATION OPTIONS
DISTINCT optimization turned on: 1 (Default)
Bias queries as outlier: 0 (Default)
%ALLINDEX optimization turned on: 0 (Default)
%NOFLATTEN optimization turned on: 0 (Default)
%NOMERGE optimization turned on: 0 (Default)
%NOSVSO optimization turned on: 0 (Default)
%NOUNIONOROPT optimization turned on: 0 (Default)
%NOTOPOPT optimization turned on: 0 (Default)
RELATIONAL SERVER OPTIONS
Server Initialization Code: (NONE) (Default)
Server Disconnect Code: (NONE) (Default)
ただ、根っこから止めてしまうと、他の自動で動作していた並列クエリまで止まってしまうので、よく検討してから実施して下さい。
個別に停止させる
オプティマイザーが並列クエリを実施すると判断したクエリに対し、並列クエリの実行を停止する方法は「%noParallel」キーワードをクエリに付与します。
下記クエリの様に、from節の直後に「%noParallel」キーワードを付与します。
select 性別 from %noParallel developer_data.Patient2 group by 性別おわりに
今回は並列クエリの解説でした。
並列クエリは、既存のロジックを変更しなくても、容易に速度を向上させる事が可能です。
※インデックスの新規追加・変更、クエリの変更等々
ただ引き換えとして、CPUが高騰する可能性が高いです。
並列クエリの設定は、計画的に行った方が良いですね。

