


CSVファイルを読み取り、テーブルのレコードを生成する方法をご紹介します。
はじめに
今回はCSVファイルから、直接テーブルのレコードを生成する方法のご紹介になります。
この方法を使うと、生成AIで作成したCSVを取り込んで、簡単にテストデータを生成する事が可能になります。
CSVファイルを読み込む処理に関しては、下記記事を参考にしてください。

生成AIからテストデータを作成する
ざっくりとした流れは、下記2つの作業工程になります。
- 生成AIを使用し、テストデータをCSVファイルで生成する
- コマンドを使い、CSVファイルを取り込む
まずは、ゴールとなるデータクラスです。
ここにテストデータを生成する事が、今回のゴールとします。
Class developer.csv.Patient Extends %Persistent
{
Index unique On (storeCd, patientId, zUpdateCount) [ PrimaryKey ];
Index i1 On (storeCd, patientId) [ Data = (漢字氏名, カナ氏名, 生年月日) ];
Property xActive As %Boolean [ InitialExpression = 1, Required ];
Property zUpdateCount As %Integer [ InitialExpression = 1, Required ];
Property dele As %Boolean [ InitialExpression = 0, Required ];
Property storeCd As %String [ Required ];
Property patientId As %String [ Required ];
/// 姓_全角スペース_名
Property 漢字氏名 As %String;
/// 姓_半角スペース_名
Property カナ氏名 As %String;
/// 姓_半角スペース_名
Property ローマ字氏名 As %String;
Property 漢字旧姓 As %String;
Property カナ旧姓 As %String;
Property 性別 As %String;
Property 生年月日 As %Date;
Property 死亡日時 As %DateTime;
Property コメント As %String;
Property 新患登録日 As %Date;
Property ABO血液型 As %String;
Property RH血液型 As %String;
Property 未使用区分 As %Boolean;
}生成AIを使用し、テストデータをCSVファイルで生成する
今回CSVファイルの生成を行う生成AIは、ChatGPT(無償版)を利用します。
生成AIはプログラムとは異なり、同じ質問でも若干内容が変わったりします。
想定していないデータであれば、質問の内容などを工夫するとよいです。
今回は下記質問を行いました。
患者情報のサンプルデータを100件CSVファイルで作成して下さい。
ヘッダは、下記になります。
xActive %Boolean,zUpdateCount %Integer, dele %Boolean, storeCd %String,patientId %String,漢字氏名 %String,カナ氏名 %String,ローマ字氏名 %String,漢字旧姓 %String,カナ旧姓 %String,性別 %String,生年月日 %Date,死亡日時 %TimeStamp,コメント %String,新患登録日 %Date,ABO血液型 %String,RH血液型 %String,未使用区分 %Boolean
また、各列の条件は下記になります。
storeCdは1173固定
patientIdは10桁の数値で、先頭4文字は1173、残り6文字はランダムの数値
漢字氏名はそれぞれ別の名前で、名字と名前の間に全角スペースを挟む
カナ氏名は、漢字氏名の読みを半角カナで作成し、名字と名前の間に半角スペースを挟む
ローマ字氏名は、漢字氏の読みをローマ字アルファベットで作成し、名字と名前の間に半角スペースを挟む
性別は、男、女、不明の3パターンで男と女を多めに
生年月日は、1900-01-01から2024-10-14まで
新患登録日は、1900-01-01から2024-10-14まで
死亡日時は"" or ランダム値でYYYY-MM-DD hh:mm:ss形式で、""がかなり多め
コメントは、適当な記事のタイトルを20字以内で創作してください
未使用区分は、1と0の値で、10:1の比率で1を多め
xActiveとzUpdateCountは1固定
deleは0固定※細かく指定すればするほど、テストデータの精度が上がります。
必要な情報がCSVで生成できたら、「患者情報サンプルデータをダウンロード[>_]」よりCSVファイルをダウンロードしましょう。

CSVファイルを取り込む
CSVファイルが「utf-8」である場合、BOMをつけて下さい。
VS Codeなどで簡単に変換できます。
では、コマンドを実行するためターミナルを起動します。
起動したら、適宜ネームスペースを変更して下さい。
ターミナルが起動したら、下記コマンドを実行します。
s rowType = "xActive %Boolean,zUpdateCount %Integer, dele %Boolean, storeCd %String,patientId %String,漢字氏名 %String,カナ氏名 %String,ローマ字氏名 %String,漢字旧姓 %String,カナ旧姓 %String,性別 %String,生年月日 %Date,死亡日時 %TimeStamp,コメント %String,新患登録日 %Date,ABO血液型 %String,RH血液型 %String,未使用区分 %Boolean"
s fileName = "D:\Temp\csv\読み込み\patient_data_sample_bom.csv"
s clsNm = "developer.csv.Patient2"
s result = ##class(%SQL.Statement).%ExecDirect(,"call %SQL_Util.CSV_TO_CLASS(1, ?, ?,,,1, ?)", .rowType, fileName, clsNm)
w !,"SQLCODE:"_result.%SQLCODE,", ","ROWCOUNT:"_result.%ROWCOUNT実行結果が下記になります。
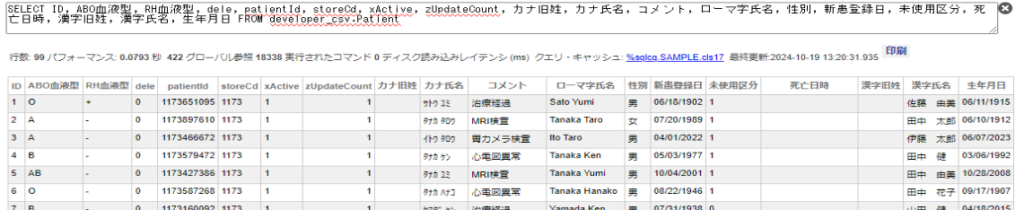
見事100レコードの作成ができました!

どこに100レコードができたの?
100レコードが生成されたのは、コマンド実行時に指定した「存在しないクラス」になります。
コマンド実行後、該当クラスが生成され、CSV取り込み関数である「Import」も生成されています。
Class developer.csv.Patient2 Extends %Library.Persistent [ Not Abstract, DdlAllowed, Not LegacyInstanceContext, ProcedureBlock ]
{
Property xActive As %Library.Boolean [ SqlColumnNumber = 2 ];
~~ 略 ~~
Property 未使用区分 As %Library.Boolean [ SqlColumnNumber = 19 ];
ClassMethod Import(pSelectMode As %Library.Integer = {$zu(115,5)}, pFileName As %Library.String(MAXLEN=""), pDelimiter As %String = ",", pQuote As %String = """", pHeaders As %Integer = 0, ByRef pRecordCount As %Integer) As %Library.Integer [ SqlProc ]
{
set tStatementId = $SYSTEM.Util.CreateGUID(), tCounter = 0, pRecordCount = 0
set tPreparedStatement = ##class(%SQL.DynamicStatement).Prepare(tStatementId,..#ROWTYPE,pDelimiter,pQuote,,,0,"CSV")
if $Isobject(tPreparedStatement) {
set tImporter = tPreparedStatement.%New(tPreparedStatement,,pFileName,pDelimiter,pQuote)
if $Isobject(tImporter) {
do ..%DeleteExtent(,.tDeleted,.tInstances,1)
// burn the column headers
for tPtr = 1:1:pHeaders { do tImporter.%Next() }
while tImporter.%Next() {
set tMe = ..%New()
if 'pSelectMode {
set tMe.xActive = tImporter.%GetData(1)
~~ 略 ~~
set tMe.未使用区分 = tImporter.%GetData(18)
}
elseif pSelectMode = 1 {
set tMe.xActive = $s('$system.CLS.IsMthd("xActiveOdbcToLogical"):tImporter.%GetData(1),1:tMe.xActiveOdbcToLogical(tImporter.%GetData(1)))
~~ 略 ~~
set tMe.未使用区分 = $s('$system.CLS.IsMthd("未使用区分OdbcToLogical"):tImporter.%GetData(18),1:tMe.未使用区分OdbcToLogical(tImporter.%GetData(18)))
}
elseif pSelectMode = 2 {
set tMe.xActive = $s('$system.CLS.IsMthd("xActiveDisplayToLogical"):tImporter.%GetData(1),1:tMe.xActiveDisplayToLogical(tImporter.%GetData(1)))
~~ 略 ~~
set tMe.未使用区分 = $s('$system.CLS.IsMthd("未使用区分DisplayToLogical"):tImporter.%GetData(18),1:tMe.未使用区分DisplayToLogical(tImporter.%GetData(18)))
}
set tStatus = tMe.%Save()
if $$$ISOK(tStatus) { set tCounter = tCounter + 1 }
}
}
}
set %sqlcontext.%SQLCODE = 0
set %sqlcontext.%ROWCOUNT = tCounter
set pRecordCount = tCounter
quit tCounter
}
Parameter ROWTYPE = "xActive %Boolean,zUpdateCount %Integer, dele %Boolean, storeCd %String,patientId %String,漢字氏名 %String,カナ氏名 %String,ローマ字氏名 %String,漢字旧姓 %String,カナ旧姓 %String,性別 %String,生年月日 %Date,死亡日時 %TimeStamp,コメント %String,新患登録日 %Date,ABO血液型 %String,RH血液型 %String,未使用区分 %Boolean";
}この段階では「developer.csv.Patient2.cls」にデータが作成されているため、下記コマンドを使い本来のデータクラスにデータを移し、インデックスの再作成を行います。
m ^developer.csv.PatientD = ^developer.csv.Patient2D // マージ
d ##class(developer.csv.Patient).%BuildIndices() // インデックス再作成
d $system.OBJ.Delete(clsNm,"e") // developer.csv.Patient2.clsの削除全ての作業が完了したので、データの確認を行います。
SQLで確認したところ問題なさそうです。
100件のテストデータが完成しました!
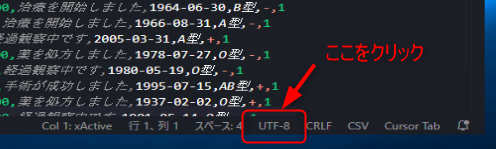
UTF-8にBOMをつける方法
まずは、VS Codeの画面右隅に「UTF-8」と記載している箇所をクリックします。
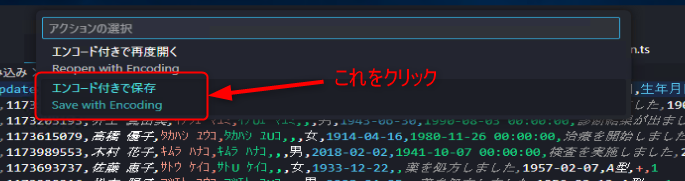
次に画面上部の「エンコード付きで保存」をクリックします。
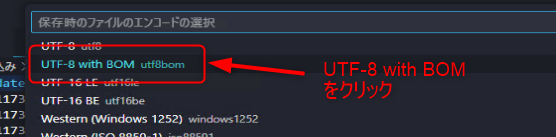
最後に「UTF-8 with BOM」をクリックして完了です。
おまけ
コマンド実行時に、存在しないクラスを指定する事で、クラスと取り込み関数「Import」の生成を行いました。
結論から言うと、クラス「developer.csv.Patient.cls」に取り込み関数「Import」さえあれば、架空のクラスを作成する必要がありません。
つまり、developer.csv.Patient2.clsの「Import」をそのまま移植すれば、以降は架空のクラスを指定しなくても取り込みが可能になります。
ベースがある程度できているので、修正も楽ですね。
CSVを修正してコマンドの実行を楽にする
CSVのヘッダを少し加工すると、取り込みコマンドが少し楽になります。
ヘッダの先頭に「–(半角ハイフン)」を記載すると、その行はコメントとして認識します。

CSVのヘッダ行を活かす事ができるので、引数に「rowType」を指定する必要がありません。
代わりに、「UTF8」を追加します。
※ヘッダ行を読み込むのに、引数「UTF8」が必要
s fileName = "D:\Temp\csv\読み込み\patient_data_sample_bom.csv"
s clsNm = "developer.csv.Patient2"
s result = ##class(%SQL.Statement).%ExecDirect(,"call %SQL_Util.CSV_TO_CLASS(1,, ?,,,,?,?)", fileName, clsNm, "UTF8")
w !,"SQLCODE:"_result.%SQLCODE,", ","ROWCOUNT:"_result.%ROWCOUNTおわりに
いかがだったでしょうか。
生成AI(今回はChatGPT)を利用し、テストデータの作成を簡易に行う方法のご紹介でした。
また、生成された関数「Import」を加工することで、取り込みPGが比較的容易に作成できたりもします。
元々取り込み処理自体ができていますからね。
※関数名・引数を変更し、各プロパティ毎に沿った変更を追加で行う必要あり
工夫次第で、いろいろと捗りますね。

