


はじめに
「𩸽」美味しいですよね。
「𩸽」開きを焼いて、大根おろしと共に食べる。最高です!
でも、プログラムの世界では「𩸽」は、まったくオイシクナイデス。
今回は、IRIS/Cacheでの「𩸽」のおいしい料理方法をご紹介いたします。
サロゲートペアとは
そもそもサロゲートペアとは何?
日本語のUnicodeでは1文字につき、基本2バイト文字になります。
ただ、使用したい文字が増えたため、1文字4バイトとして新たに使用できるようにしました。

IRIS/Cacheではどうなるか?
サロゲートペアの事が分かったので、IRIS/Cacheではどう振舞うか確認したいと思います。
s str="𩸽"
w $l(str)
一文字しか無いのに、文字の長さが2文字と表示されました。
4バイト文字のため、誤検知していますね。
$length()で誤検知しているので、$extract()でも怪しい動作をします。
4バイト中の2バイトを切り取ってしまうので、正しい文字として表示できません。
s str="𩸽が食べたい"
w $e(str)_"を食べるぞ"
流石に文字の幅($zwidth)は、正常に算出されましたね。
w $zwidth(str)
文字の反転($reverse)
w $reverse("あい𩸽えお")
検索の$findも「お」の位置がずれますね。
w $f("あい𩸽えお","お")
w $f("あいうえお","お")
文字コードの取得($ascii, $char)
w $a("𩸽") // 文字 > 文字コード
w $c(55399) // 文字コード > 文字
w $a("あ")
w $c(12354)
文字を操作するObjectScriptは、どれも軒並み全滅しているのが確認できました。
あぁ、「𩸽」オイシクナイヨ…(笑
対応策
各種ObjectScriptは、コマンドの先頭に「w」を付ければ大体OKです!(笑
どのコマンドも、サロゲートペアが含まれていなくても正常に動作します。
ただ、ちょっぴり遅いとドキュメントに記載されています。
サロゲートペアが含まれているかチェックをする
サロゲートペアに対応したコマンドは、処理が遅いと言われています。
その為、まず最初に文字列にサロゲートペアが含まれているか判断する必要があります。
w $wiswide("あいうえお")
w $wiswide("あい𩸽えお")
1が返る事で、文字列にサロゲートペアが含まれている事を取得できます。
文字数を取得する
$length()では正常に取得出来なかった文字数も、$wlength()で取得する事が出来ます。
w $wl("あい𩸽えお")
w $wl("あいうえお")
文字の切り取り
$extract()ではなく、$wextract()になります。
s str="𩸽が食べたい"
w $we(str)_"を食べるぞ"
文字の反転
$reverse()は、$wreverse()になります。
w $wreverse("あい𩸽えお")
w $wreverse("あいうえお")
文字の検索
$find()は、$wfind()で対応できます。
w $wf("あい𩸽えお","お")
w $wf("あいうえお","お")
文字コードの操作
$ascii()が$wascii()になり、$char()が$wchar()で対応ができます。
w $wa("𩸽") // 文字 > 文字コード
w $wc(171581) // 文字コード > 文字
w $wa("あ") // 文字 > 文字コード
w $wc(12354) // 文字コード > 文字
通常版とどのくらい処理速度が変わるんだろう?
ドキュメントを読む限りでは、サロゲートペアに対応した「w」系のコマンドは、通常版より処理速度が遅いと記述されています。
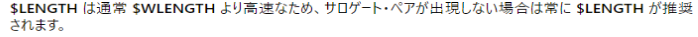
実際、どの程度処理速度に差があるのか、確かめてみます。
$length()と$wlength()の速度差
$length()と$wlength()の速度をチェックしてみましょう。
ClassMethod checklengthSpeed(cnt As %Integer = 10000, str As %String)
{
s start = $zh
f pos = 1:1:cnt s str = $l(str)
w !,"通常:"_($zh-start)
s start = $zh
f pos = 1:1:cnt s str = $wl(str)
w !,"対応:"_($zh-start)
}文字数を20文字にして確かめてみます。

あれ?あまり時間差がないゾ・・・
同じ処理の反復は、差が出にくいのでしょうか。
文字数を100文字にして確認
s str=str_str_str_str_str
w $l(str)
d ##class(developer.Sample).checklengthSpeed(10000,str)
この検証方法では、両コマンドの差は誤差レベルと思えます・・・
$extract()と$wextract()で速度差を比較する
$extract()は使い方が幅広いので、文字列中の1文字を切り取る形での速度差を検証してみたいと思います。
ClassMethod checkextractSpeed(cnt As %Integer = 10000, str As %String, pos as %Integer = 10)
{
s start = $zh
f pos = 1:1:cnt s str = $e(str,pos)
w !,"通常:"_($zh-start)
s start = $zh
f pos = 1:1:cnt s str = $we(str,pos)
w !,"対応:"_($zh-start)
}$length検証と同じく20文字から始めてみたいと思います。
20文字中の10文字を切り取る形でスタート!
s str = "あいうえおかきくけこさしすせそたちつてと"
d ##class(developer.Sample).checkextractSpeed(10000,str)
あれ、サロゲートペア対応の方が若っっっ干早いですね。
ほぼ誤差レベルの差なので、気にする必要は無さそうです。
とりあえず、100文字中の40番目を切り取る形で検証してみます。
s str = str_str_str_str_str
w $l(str)
d ##class(developer.Sample).checkextractSpeed(10000,str,40)
・・・
オカシイな。
まぁ、うん。ほぼ誤差なので気にしない事にします。
終わりに
ドキュメントを読む限りでは、サロゲート対応版より通常版のコマンドの方が高速のため、そちらを使用する事を推奨していますが、検証した限りではあまり速度差が無いですね。
もっと文字数の多い文字列であれば、差がでてくるのでしょうか。
一先ず、$wiswide()を利用して、サロゲートペアが文字列中に含まれているかを判断し、コマンドの使い分けをした方が無難と考えます。
以上、サロゲートペアの美味しい料理の仕方でした!

